
Die WCET-Berechnung erfolgt in mehreren Schritten:
- Rekonstruktion des Kontrollflusses aus den ausführbaren Binärdateien des zu analysierenden Systems
- Value-Analyse: Bestimmung von Schleifengrenzen und Berechnung von Adreßbereichen für Instruktionen, die auf den Speicher zugreifen
- Cache-Analyse: Klassifizierung der Speicherzugriffe als Cache-Treffer oder Cache-Verfehlen
- Pipeline-Analyse: Vorausberechnung des Verhaltens der Prozessor-Pipeline
- Pfadanalyse: Bestimmung des Worst-Case-Ausführungspfades
Bei modernen Mikroprozessoren sind viele dieser Teilaufgaben sehr komplex.
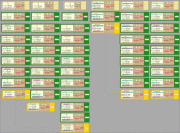
Die Anordnung der einzelnen Schritte ist in dem etwas vereinfachten Bild rechts zu sehen. Die Ergebnisse der Value-Analyse werden von der Cache-Analyse gebraucht, um das Verhalten des (Daten-)Cache vorherzusagen. Die Ergebnisse der Cache-Analyse werden wiederum an die Pipeline-Analyse weitergereicht, um Pipeline-Staus aufgrund von Cache-Verfehlen vorherzusagen. Die kombinierten Ergebnisse der Cache- und der Pipeline-Analyse werden benutzt, um die Ausführungszeit der einzelnen Programmpfade zu berechnen.
Die Unterteilung der WCET-Bestimmung in einzelne Schritte hat den Vorteil, daß in jedem Schritt eigene, speziell für diesen Schritt optimierte Analysemethoden zum Einsatz kommen können. Die Value-, Cache- und Pipeline-Analyse basieren auf der sogenannten abstrakten Interpretation. Die Pfadanalyse erfolgt durch ganzzahlige lineare Optimierung (ILP).
Rekonstruktion des Kontrollflusses aus Binärdateien
Der Ausgangspunkt der WCET-Analyse ist ein von einem Compiler erzeugtes ausführbares Binärprogramm sowie optional durch den Systementwickler gemachte Zusatzangaben, z. B. zur Anzahl der möglichen Schleifendurchläufe, Obergrenzen für Rekursionen, udgl.
Im ersten Schritt liest aiT das zu analysierende Programm und rekonstruiert daraus den Kontrollfluß. Dies erfordert einige Kenntnisse über die zugrundeliegende Hardware – z. B., welche Instruktionen Verzweigungen oder Aufrufe darstellen. Der rekonstruierte Kontrollfluß wird mit einigen Zusatzinformationen versehen, die von den nachfolgenden Analysen gebraucht werden. Anschließend wird der Kontrollfluß in das Zwischenformat CRL (Control Flow Representation Language) übersetzt, das speziell entwickelt wurde, um Analysen und Optimierungen auf der Ausführungsebene zu vereinfachen. Der annotierte Kontrollflußgraph im CRL-Format dient als Eingabe für die darauffolgenden Analysen.
Value-Analyse
Die Value-Analyse bestimmt die Wertebereiche von Registerwerten und Speicherzellen. Dies ermöglicht die Bestimmung von Schleifengrenzen und die Auflösung von indirekten Speicherzugriffen. Mit dem optionalen ValueAnalyzer-Zusatzmodul können Sie diese Ergebnisse interaktiv erkunden – alle Register- und Speicherzelleninhalte, für jede Instruktion, in jedem Ausführungskontext.
Cache-Analyse
In diesem Teilschritt wird für jeden Speicherzugriff in jedem möglichen Ausführungsszenario überprüft, ob die benötigten Daten im Cache vorhanden sind. Dabei werden alle Speicherzugriffe in die folgenden Kategorien unterteilt:
| always hit | Der Speicherzugriff führt immer zu einem Cache-Treffer (Cache-Hit). |
| always miss | Der Speicherzugriff führt immer zu einem Cache-Verfehlen (Cache-Miss). |
| persistent | Der Speicherblock, auf den der Zugriff erfolgt, wird höchstens einmal geladen. |
| unreachable | Der Code wird nie erreicht. |
| not classified | Der Speicherzugriff kann keiner der obigen Kategorien zugeordnet werden. |
Für bestimmte Prozessoren berechnet aiT darüberhinaus Unterbrechungskosten durch Cache-Effekte. Dies geschieht mittels der sogenannten UCB-Analyse.
Pipeline-Analyse
 In
diesem Teilschritt wird das Verhalten der Mikroprozessor-Pipeline
formal modelliert, um die Ausführungszeit von einzelnen Instruktionen
und von Flußsequenzen (Basisblöcken) zu bestimmen. Dabei wird stets
der aktuelle Pipeline-Zustand berücksichtigt, insbesondere
die Ressourcenbelegung, der aktuelle Inhalt der Prefetch-Queue,
die Gruppierung der Instruktionen und die Klassifizierung
der Speicherzugriffe als Cache-Hits oder -Misses. Das Ergebnis
der Analyse ist die Ausführungszeit einer jeden Instruktion
in jedem einzelnen Ausführungskontext.
In
diesem Teilschritt wird das Verhalten der Mikroprozessor-Pipeline
formal modelliert, um die Ausführungszeit von einzelnen Instruktionen
und von Flußsequenzen (Basisblöcken) zu bestimmen. Dabei wird stets
der aktuelle Pipeline-Zustand berücksichtigt, insbesondere
die Ressourcenbelegung, der aktuelle Inhalt der Prefetch-Queue,
die Gruppierung der Instruktionen und die Klassifizierung
der Speicherzugriffe als Cache-Hits oder -Misses. Das Ergebnis
der Analyse ist die Ausführungszeit einer jeden Instruktion
in jedem einzelnen Ausführungskontext.
Pfad-Analyse
Basierend auf den Ergebnissen der Mikroarchitektur-Analysen liefert die Pfad-Analyse eine sichere Vorhersage der WCET. Dazu wird der Kontrollfluß des Programms mithilfe der ganzzahligen linearen Optimierung modelliert. Für jede Basisblockkante wird die Anzahl ihrer Durchläufe berechnet.
Spezialbehandlung für Schleifen und rekursive Prozeduren
Schleifen und rekursive Prozeduren sind vom besonderen Interesse, da sie für den größten Teil der Ausführungszeit verantwortlich sind. Sie erfordern eine Spezialbehandlung – andernfalls leidet die Genauigkeit der Cache- und Pipeline-Analyse-Ergebnisse ganz erheblich.
In der Regel werden beim ersten Durchlauf einer Schleife die benötigten Daten erst in den Cache geladen, während alle nachfolgenden Durchläufe die meisten dieser Daten bereits im Cache vorfinden. Somit unterscheidet sich der Cache-Kontext des ersten Schleifendurchlaufs in aller Regel ganz erheblich von dem Kontext aller anderen Durchläufe.
Naive Analyse-Methoden ignorieren diese Tatsache und fassen einfach den abstrakten Cache-Zustand vor dem Eintritt in die Schleife mit dem abstrakten Zustand nach deren Verlassen zusammen. Wichtige Informationen über das eigentliche Verhalten des Systems in der Schleife gehen dabei verloren.
aiT hingegen implementiert die sogenannte „VIVU“-Methode (virtual inlining, virtual unrolling) zum virtuellen Abrollen der Schleifen. Damit können Speicherzugriffe in den unterschiedlichen Ausführungskontexten der einzelnen Schleifendurchläufe analysiert werden.
{kind=link}