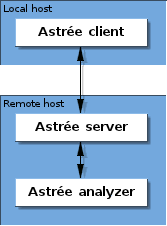
Aufbau
Astrée besteht aus zwei Teilen:
- dem Astrée-Klienten, mit dem Sie eine Analyse aufsetzen und sich die Ergebnisse anschauen können,
- dem Analyseserver, auf dem die eigentliche Analyse läuft (oder auch mehrere Analysen, jede als ein eigener Prozeß).
Der Klient bietet sowohl eine graphische Benutzerobefläche als auch Batchmode-Betrieb zur einfachen Automatisierung und Integration.
Beide Teile können auf demselben Rechner laufen. Typischerweise läuft der Server jedoch auf einem leistungsfähigeren Remote-Host und die Klienten auf den Rechnern der einzelnen Entwickler und Abteilungsleiter.
Ihre Lizenzdatei entscheidet darüber, wieviele Klienten zeitgleich auf den Server zugreifen dürfen und wieviele Analyseprozesse dort parallel laufen können.
Ihre Eingaben
Astrée arbeitet auf präprozessiertem C-Code. Auf Wunsch spart Ihnen der eingebaute Präprozessor diesen Arbeitsschritt. Anschließend wird der präprozessierte Code geparst und in eine Zwischendarstellung für die Analyse übersetzt.
Für jede Analyse können Sie einen eigenen Eintrittspunkt angeben – meistens ist das eine Funktion von besonderem Interesse für Sie, oder einfach nur
main. Astrée analysiert dann sämtliche Codeabschnitte, die von diesem Eintrittspunkt aus durch ununterbrochene sequentielle Programmausführung erreichbar sind.Sie können einen Analyse-Wrapper aufsetzen – z. B. um reaktives Systemverhalten zu modellieren. Der Wrapper wird als eine eigenständige C-Datei in die Analyse eingebunden.
Astrée kann ferner mit verschiedenen Einstellungen der Application–Binary-Schnittstelle (ABI) konfiguriert werden.
Zuletzt können Sie Astrée Zusatzinformationen zur Verfügung stellen, z. B. um die Ausführungsumgebung zu beschreiben oder die Präzision der Analyse zu steuern. Das erfolgt in einer separaten Datei, sodaß Ihr Quellcode nicht angefaßt werden muß.
Die Zusatzinformationen werden in einem leicht verständlichen Textformat angegeben, der Astrée-Annotation-Language AAL, oder einfach mit dem integrierten Annotation-Wizard erzeugt. Sie nehmen auf keine Zeilennummern Bezug, sondern auf die eigentliche Programmstruktur, und müssen somit nicht bei jeder Codeänderung angepaßt werden.
Die Ergebnisse
Das wichtigste Ergebnis der Analyse ist eine Liste von Alarmen, sprich von möglichen Laufzeitfehlern. Jeder Fehler wird zusammen mit seinem Typen angegeben sowie der genauen Stelle im Quellcode, an der er auftritt. Wenn Astrée beweisen kann, daß ein Alarm in einem bestimmten Kontext unter allen Umständen auftritt, wird dieser Alarm als ein eindeutiger Laufzeitfehler eingestuft.
Zur schnellen Orientierung wird das Gesamtergebnis in der Benutzeroberfläche mithilfe einer Ampel dargestellt:
   rot rot |
mindestens ein Laufzeitfehler | |
  gelb gelb |
keine Fehler, aber mindestens ein Alarm vom Typ A | |
 grün
und gelb grün
und gelb |
keine Fehler und keine Alarme vom Typ A, aber mindestens ein Alarm vom Typ C | |
| grün |
keine Fehler und keine Alarme | |
|
||
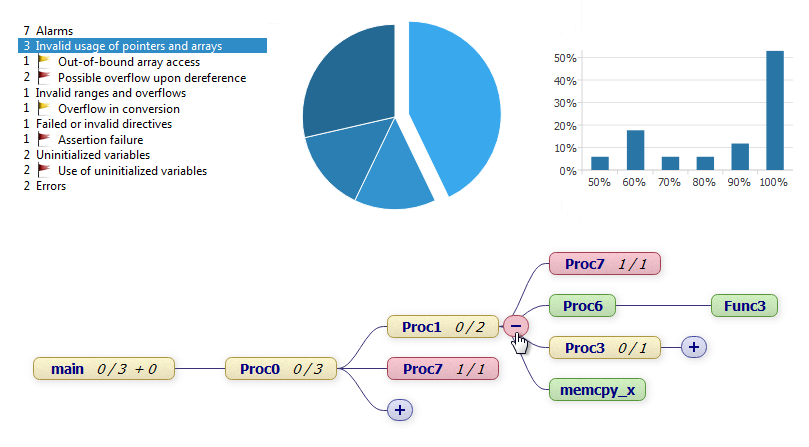
Darüberhinaus stehen Ihnen vielfältige interaktive Detailansichten, Tabellen und Graphen helfend zur Verfügung.
Zusätzlich überprüft der integrierte RuleChecker Ihren Code auf die Einhaltung von MISRA-Regeln und berechnet vielfältige Code-Metriken wie Comment-Dichte und zyklomatische Komplexität.
Ferner kann Astrée benutzerdefinierte Annahmen
zu funktionalen Programmeigenschaften überprüfen, ähnlich der
„assert“-Diagnostik. Wird eine Annahme
nicht als verletzt gemeldet, gilt die Korrektheit des dazugehörigen
C-Ausdrucks als bewiesen.
Sollten unentbehrliche Daten fehlen oder uneinlesbar sein, wird die Analyse stets mit einem Fehler abbrechen.
Astrée zeigt Ihnen auch an, wenn bestimmte Codeabschnitte nicht analysiert wurden. Sofern die Analyse keine Laufzeitfehler gefunden hat, gelten solche Abschnitte als garantiert unerreichbar vom angegebenen Startpunkt aus („toter Code“).
Für Dokumentation und Zertifizierung können detaillierte Analyseberichte gespeichert werden. Ebenso können Sie das gesamte Analyse-Projekt mit allen Dateien, Einstellungen, Ihren Annotationen und Kommentaren abspeichern.
Fehlerbehebung
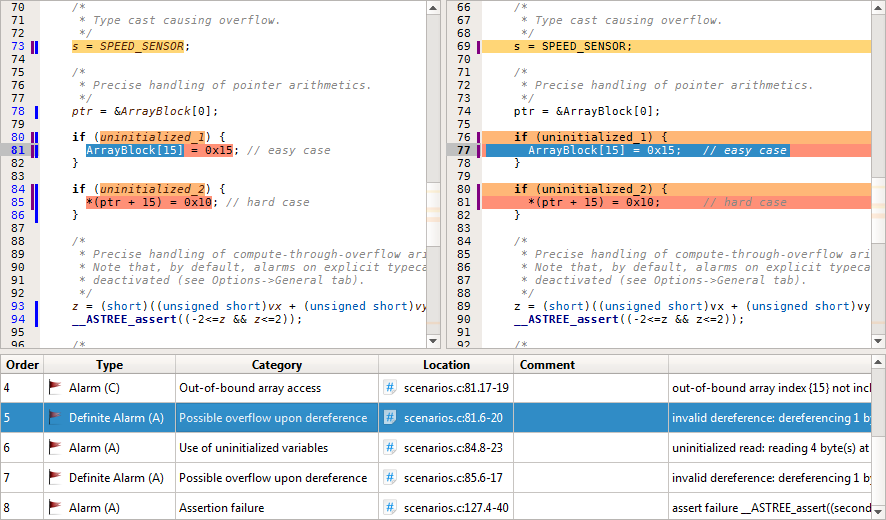
Die gefundenen Laufzeitfehler können Sie in Ihrem Astrée-Klienten interaktiv untersuchen, mit Kommentaren versehen oder gleich im integrierten Code-Editor beheben.
Eventuelle Fehlalarme können Sie mit AAL-Annotationen als solche kennzeichnen, damit sie nicht wieder auftreten. Alternativ können Sie die Analyseeinstellungen anpassen, oder die Analysegenauigkeit an den gewünschten Stellen erhöhen.
Danach können Sie die Analyse neu starten und die verbesserten Ergebnisse begutachten.
Bei Bedarf wiederholen Sie diese Schritte, bis keine Alarme mehr vorliegen. Dann ist die Abwesenheit von Laufzeitfehlern in Ihrem Code formal bewiesen.
Querverweis
Alle Sicherheitseigenschaften, die Sie mit Astrée für Ihren C-Code nachgewiesen haben, können Sie verlustfrei auf Ihren Binärcode übertragen, indem Sie unseren formal verifizierten Compiler CompCert benutzen. Es ist der einzige Compiler weltweit, der Ihnen diese Sicherheit bietet.
Konfiguration
Jede Astrée-Analyse kann auf vielfältige Weisen konfiguriert werden:
- Optionen
- Einstellungen der Präzision und der abstrakten Domains
- Aspekte der Semantik
- Umfang und Detailliertheit der Ausgaben
- Direktiven
- semantische Informationen, z. B. Wertebereiche und Invarianten
- Parameter für lokale Anpassungen der Analysepräzision
- ABI-Einstellungen
- Größe der atomaren Typen
- Alignment-Einstellungen
- Byte-Reihenfolge
- Vorzeichen von Char und Bitfield
- usw.
- Filter
z. B. zum Ignorieren von Inline-Assembly oder ungenormten Keywords - Wrapper- und Stub-Code
{kind=link}
{kind=link}