Targets
- TimingProfiler for V850 E1, V850 E2 and RH850 is now available.
a³ for V850 has been renamed to a³ for V850/RH850, as TimingProfiler for RH850 is now included in this package. - StackAnalyzer for AMD K6-2E+ is now available.
- Support for e500 has been discontinued.
Integration with dSPACE TargetLink
The handling of interpolation routines has been improved.
GUI
- Major revamp of the user interface.
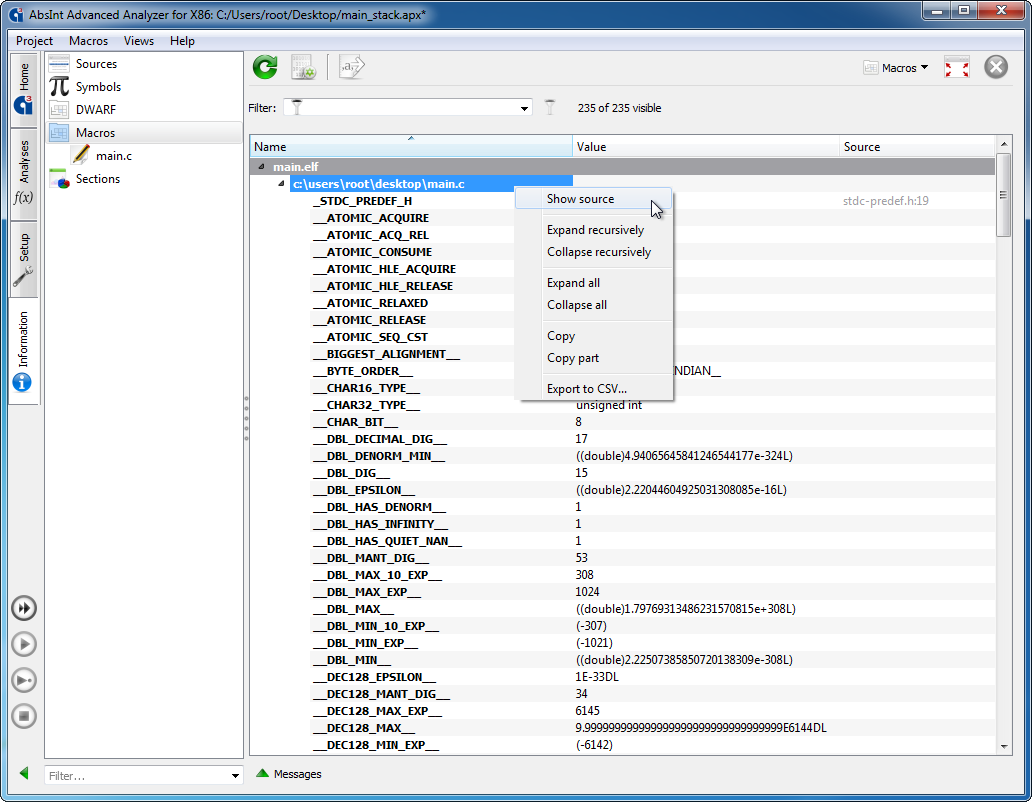
- The new Macros view lists macros from source code, extracted from DWARF debug info if available.
- Improved DWARF debug information view:
- much faster visualization of the debug information, reduced memory consumption and enhanced performance
- path replacements are applied to enable links between the DWARF view and the source code
- extended search capabilties
- In the DWARF view, searching for an address will now also look for it inside global variables or functions.
- The “Variable usage (context)” view now offers a context menu for jumping from a variable to the instructions that access it in the call graph or disassembly.
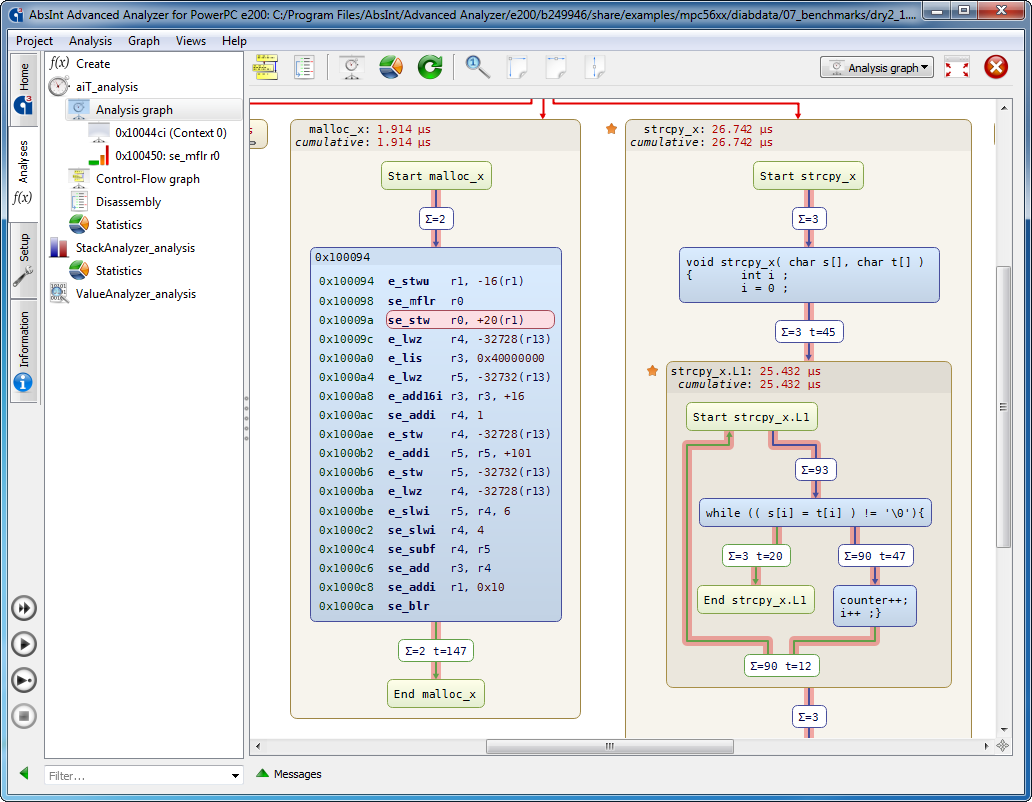
- Faster loading of graph visualization when source code is displayed.
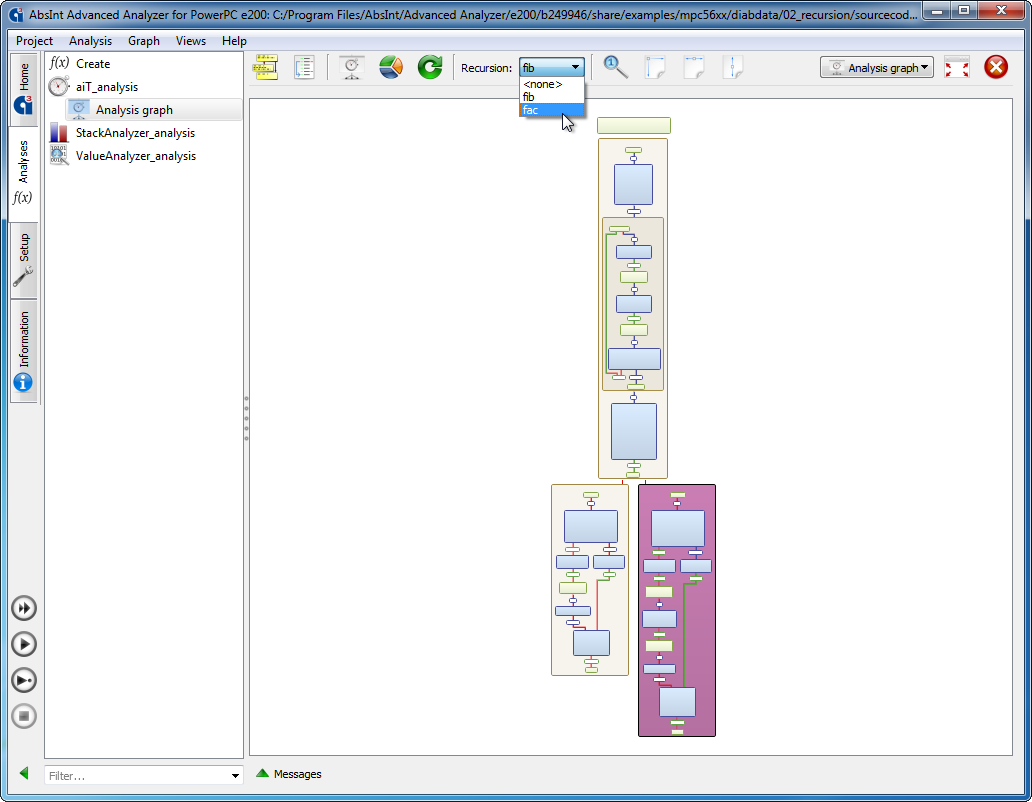
- In the Graph view, recursive functions can now be highlighted using a dropdown in the toolbar.
- By default, the Message view no longer shows notes and progress indicators. Only errors, warnings and infos are shown. Notes and progress can still be shown on request.
- New option “Extract constant memory regions” to consider sections and global variables as constant (non-writable) if they are marked as constant in the DWARF debug information. If the executable reader finds any data values in such constant regions, these values will be used in resolving computed branches and calls, and in value analysis.
- TriCore: you can now specify the CSFR base address, i.e. the base
address that is used by
mfcrandmtcrinstructions to compute the addresses of the memory-mapped Core Special Function Registers (CSFRs).
AIS annotations
- New AIS2 annotations:
stack effect
increases or decreases the stack level.# increases the stack level by 8 bytes instruction "updateState" -> call(3) { stack effect: 8 bytes; } # decreases the stack level by 64 bytes routine "triggerUpdate" { stack effect: -64 bytes; }possibly exits
instructs the value analysis to handle each loop-iteration end as a potential exit of the analyzed program.loop "process.L1" { bound: 0 .. 10; possibly exits; }In this example, the routineprocesscontains a single endless loop. Without the newpossibly exitsannotation in place, the value analysis would consider the loop to be a deadend and mark it as infeasible. With the annotation, however, the value analysis will treat the ends of the first ten loop iterations as potential program exits, allowing you to obtain analysis results for these ten iterations.suppress message
for suppressing a message with a given ID (for example, a decoder warning that the binary is non-statically linked).suppress message: 1033;
- functor to access values of enumerator constants. For example,
given the C enumerated type declaration
enum cardsuit { CLUBS = 1, DIAMONDS = 2, HEARTS = 4, SPADES = 8 };the new AIS2 enum functorenum("HEARTS")will yield the value ofHEARTS, i.e.4. - support for regular expressions for annotating multiple program points
or areas at once.
# annotate handleInput0 through handleInput9 # and handleMessage0 through handleMessage9 routine match("handle(Input|Message[0-9])") { # ... } - annotation to assert that a call instruction does call
a specific set of routines.
# assert that call targets cmk, cma, and cmo exist instruction -> call(2) assert calls: "cmk", "cma", "cmo";
- Improved flexibility of the
area contains dataannotation. - AIS1 and AIS2 area annotations can now be mixed without any restrictions.
- The annotation
instruction <ProgramPoint> end;
is now written asend: <ProgramPoint>;
This allows multiple program ends to be specified in a single annotation, for example:end: 0x4040, 0x192c;
Decoding
- Improved extraction of DWARF debug information.

- Improved handling of call target annotations using AIS2 complex area definitions referring to arrays of packed structure types.
- Improved automatic decoding of computed call tables using DWARF debug information where available.
- Improved Intel HEX reader.
- Improved handling of sizes for architectures with non-byte quanta (one address space step ≠ 8 bit).
- ARM:
- Improved automatic switch table decoding.
- Improved automatic decoding of computed call tables.
- Improved handling of IT blocks containing illegal or unsupported instructions.
- Improved automatic detection of instruction set (ARM or THUMB) for routines.
- Improved output of mnemonics including their guard in THUMB IT blocks.
- C16x:
- Improved automatic switch table decoding.
- Improved guessing of stack and data page pointers.
- Fixed symbol table entries by discarding their size information if the symbol size exceeds the page.
- FR81: further improved switch table decoding of Fujitsu FR81 compiler.
- PPC: improved automatic decoding of switch and call tables for GHS.
- SPARC:
- Improved automatic switch table decoding.
- Improved resolution of computed calls via function pointers.
- TriCore:

- Improved decoding of code optimized with Tasking compiler (code factorization/ .cocofun*).
- Improved automatic decoding of switch tables for GCC.
- V850:
- The SYSCALL base pointer (SCBP) can now be specified in the Hardware view to resolve syscalls automatically during decoding.
- Improved switch table resolution.
- Improved call table patterns.
- Improved guessing of the ROM SDA base.
- x86:
- New and improved decoder.
- Generalized iterative decoding.
- Improved support for GCC 4.9.x.
Stack and value analysis
- Stack analysis and value analysis for ARM, M68020, and x86 have been ported to the new EVA value analysis framework. This implies changes in analysis behavior and precision, see the corresponding notes in release 14.10.
- EVA targets (currently ARM, C28x, FR81, M68020, PowerPC, SPARC, TriCore, V850, and x86):
- Improved stack analysis, faster value analysis, more precise loop analysis.
- Improved analysis precision for:
- recursive programs
- complex conditions
- saturated arithmetic operations
- division overflow
- zero/sign extension
- 64-bit load/stores of 32-bit register pairs
- user-given annotations “
instruction X accesses Y” - accesses to spanning multiple constant/read-only memory regions
- the last loop iteration of loops annotated by the user (not executing parts that lead to the next iteration that is not feasible anymore)
- guarded execution and conditional moves
- conditional returns and multiple loop exits
- Further improved the precision by intersecting callee save values with values propagated from the called routine.
- New option to allow the use of DWARF debug information to restrict array accesses during the value analysis. If this option is enabled, the DWARF debug information is used to determine which array an access belongs to; if it is less precise than the complete array range, it will be restricted to a valid range. Restricted accesses will be labeled as such in the text and XML report, for both stack and value analysis. Stack analysis will output only the restricted accesses (marked as "restricted" in the text report, and with the bool "restricted_only" in the XML report).
- Text and XML reports for value analysis now include the written and read values for memory accesses. The interactive value analysis also allows viewing this information per context.
- Improved output of accesses variables in value analysis reports
and interactive analysis. For example, instead of
instruction 0xffc0048e writes to [0x00000680]:4 (part of '_Array2Glob' / part of 'Array2Glob')
you will get the concrete element that is hit, if possible:instruction 0xffc0048e writes to [0x00000680]:4 ('Array2Glob[8][7]') - The GUI now allows specifying not only the threshold for imprecise reads but also for imprecise writes.
- The GUI now allows specifying the widening delay. This enables finetuning the number of fixed-point iteration steps after which the widening is applied at a widening point (e.g. a loop head).
- At widening points (e.g. start/end blocks of loops or routines), the interactive value analysis view now enables querying which registers or memory cells got lost because of the widening.
- More precise handling of returns with multiple return targets (e.g. loops with multiple exits and calls that either return normally or immediately).
- Reintroduced support for stack-modifying loops. Stack analysis is now possible after fully unrolling such loops.
- If a register is marked as preservable for an external routine, its sub-registers will now be preserved as well.
- Improved handling of multiple executables with overlapping sections.
- Faster analysis and optimized memory usage through generational garbage collection.
- Improved analysis precision of user-annotated loops that are fully unrolled.
- Iterative decoding now automatically uses larger sets of constants to collect targets for multiple calling contexts.
- Improved relational analysis by keeping track of equations containing unknown memory values.
- StackAnalyzer now incorporates the relative stack heights at the end block of a routine. This change might affect routines that end with a tail call.
- Improved speculative execution in the presence of guarded instructions.
- Improved branch splitting for complex branching conditions (like shifted registers).
- Improved branch splitting precision for sub-registers.
- Other branch splitting precision improvements, e.g.
for alignment checks in
memcpy-like loops. - Improved notification about loss of precision due to a destroyed saved stack pointer.
- Inform user about potential loss of precision if large parts
of knowledge about memory contents is lost:
eva-kalray: note #3096: in "./suites/a3/kalray/k1dp/ccsuite_o2/s4/aes.c", line 265:
In routine 'rijndaelKeySched.L10', at address 0xda8:
Losing precision since the instruction 0xda8: 'sb.add.x1 r0[r17] = r5;;' destroys 100% of the known memory content (35 cells).
(context '0x2140->"rijndaelVTKAT.clone.0", 0x1ba4->"makeKey", 0x16b0->"rijndaelKeySched", 0xc28->"rijndaelKeySched.L3"[1], 0xd64->"rijndaelKeySched.L10"[4..]') - AIS annotations can now be created for start and end blocks in the interactive value analysis.
- C28x: improved precision for conditional
xcall/xret. - FR81:
- Improved division precision.
- Analyzer assumes calling conventions for software
interrupts via
int.
- PowerPC
- Improved precision for bool data type and boolean logic.
- Improved model for conditional branch and link: update link register if condition is false, too.
- For the
stwcxinstruction, the analysis now models the reservation failed case, too.
- TriCore:
- Improved handling of code compacted by the Tasking compiler (containing .cocofun* code factor routines).
- Improved division precision.
- Improved handling of PCXI subregisters.
- V850: improved calling conventions for
syscall.
Cache and pipeline analysis
- Improved performance of the pipeline analysis framework.
- Am486: improved pipeline model.
- ARM Cortex-R4F:
- Improved handling of speculative memory accesses in the pipeline model.
- Improved pipeline model for guarded execution.
- Pipeline analysis informs about not supported definitive misaligned accesses.
- i386:
- Improved pipeline model.
- Improved handling of data dependencies.
- M68020:
- Improved pipeline model.
- Improved alignment handling of imprecise memory accesses.
- e300, PPC750, MPC7448, 7448s, 755, 755s:
- Removed split type “PCI jitter”. Those splits are now accounted for by the split type “jitter”.
- Splits caused by imprecise target latencies of memory accesses are now accounted for by the split type “variant execution time”.
Path analysis
- Faster prediction-file–based path analysis and snippet WCET evaluation.
- Improved numerical stability of the CPLEX ILP solver driver.
- Global snippet evaluations are now possible if the start and the end are not in the same routine. Still the snippet must be a single-entry single-exit region (see the user manual).
Visualization and reporting
- By default, only the output of the final decoding and analysis round for iterative decoding is printed to text/XML reports. The GUI offers an option for enabling the output of all rounds.
- Callstrings will now show the address of the call instruction rather than
that of the call block, and only report the current unroll iteration
of loops, indicating cumulative contexts with a “
..”.Old New ..., 0x30->"main.L1"[1/2..] ..., 0x30->"main.L1"[2/2..]
..., 0x34->"main.L1"[1] ..., 0x34->"main.L1"[2..]
call block address,
current iteration,
default/max unrollingcall instruction address,
current iteration,
“..” for cumulative - Implemented driver tool to perform XQueries.