 Improved side bar |
 Improved result views |
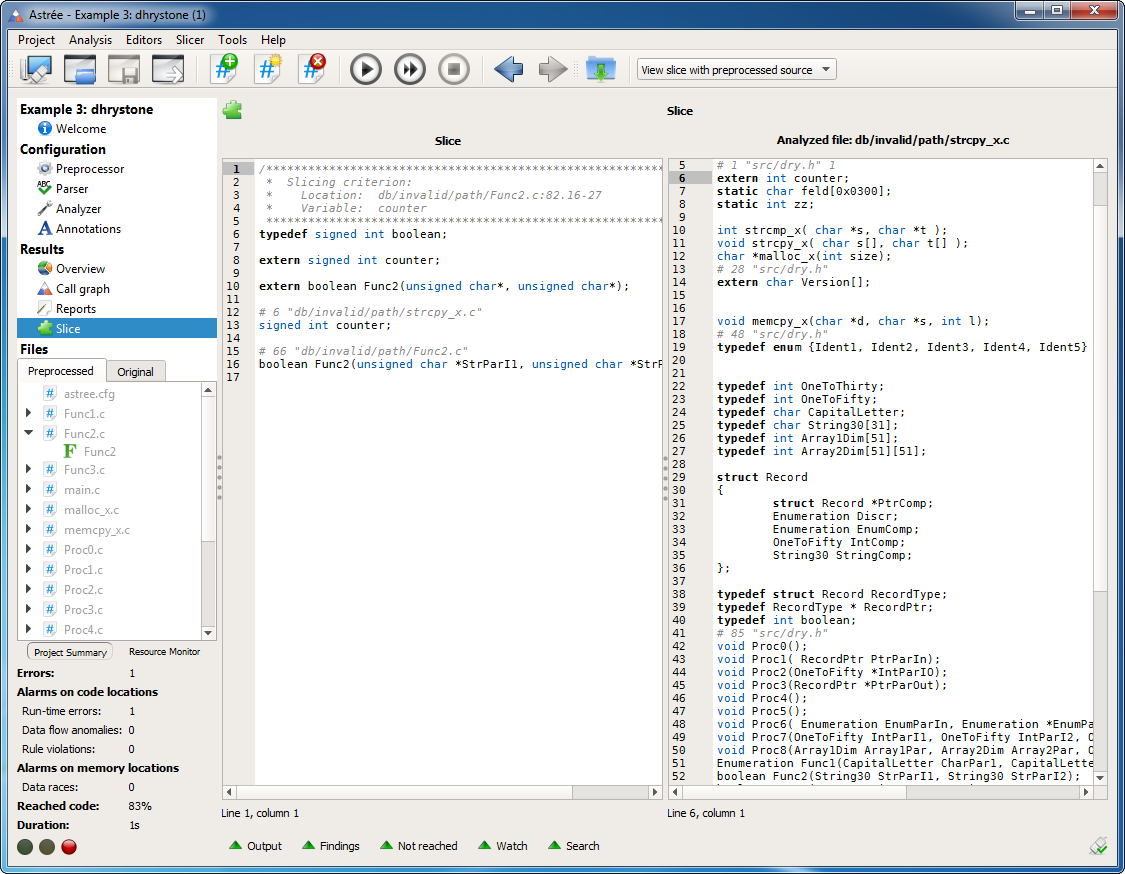 Program slicer |
- Red Hat Enterprise 5 is no longer supported. The minimum requirement is now Red Hat Enterprise 6 (CentOS 6) or compatible distributions.
- In addition to the installer that requires administrator rights, Astrée is now also available as a simple ZIP archive that can be unpacked and used without installation.
- Improved support for displays with high dpi values.
- It is now possible to export a project with all its revisions into
a single
.aaffile. - The Safety Manual now also addresses Astrée’s relation to the safety standards IEC-61508 and Cenelec EN-50128.
- Automatic conversion of analysis projects from previous Astrée versions to release 16.04 does not preserve the preprocessing configuration. To circumvent this restriction, export the preprocessing configuration to DAX using your old version and import the DAX file into your analysis project after converting it to release 16.04.
Performance
- The analysis server can now handle a large number of analysis projects and revisions more efficiently.
- Computing potentially shared variables is much faster now, particularly for larger analysis projects.
- Faster loading of projects with many AAL annotations.
- Faster loading of comments for alarms.
- Faster generation of large report files.
- Optimized performance and memory consumption
when the option
separate-functionis used in an analysis with multiple asynchronous tasks.
Analysis
- The new Gauge domain infers linear relations between the program
variables and the loop counters and thus improves analysis precision
inside of loops. It is activated via the new option
gauges=yes. Additionally, it provides notifications about loops for which no upper loop bound can be derived. - More precise handling of
NaNand infinities when the optionkeep-float-specialsis set. - Fixed an exceptional abort of the analyzer that occurred in rare cases when evaluating complex logical expressions.
- Generalized the built-in offsetof to accept member designators
that contain array designators, e.g.
offsetof(struct S, arr[5][4].b). - Improved precision on loops with side-effects in the test.
- Improved the precision of the pre-analysis for possible ambiguities
due to side effects in expressions involving assignments
of the form
x = f(). - The analyzer now supports the use of enumeration constants as pointers to absolute addresses. This allows the analysis of code like
__ASTREE_absolute_address((int, 0x1000)); enum { ADDR = 0x1000, }; ... *(int*)ADDR = 42;
C frontend
- The C99 type
_Boolis now supported. - All kinds of K&R style function definitions are now accepted, e.g.
void f(i) int i; { ... } - Astrée now supports statement expressions (GCC extension), e.g.:
int f(void) { return 19 + ({ int x = 23; x; }); } - Fixed interpretation of bitfields whose base type is specified using typedef with the underlying type having an explicitly specified signedness.
- Added support for compound literals in global initializers.
- Astrée now accepts casts involving unnamed struct types
in expressions of the form
((T*)s)->fwhereTis an unnamed struct type. - Astrée now accepts initializers for empty structs, e.g.
struct S {} s = {}; - Removed restrictions about the use of function pointers as parameters (some cases used to be rejected by the C frontend).
Stub libraries
Added a new entry function OSEK_sequential_main
to the OSEK stub library. This entry provides an automatic
sequentialized setup for OSEK projects using an OIL configuration.
It can be used to detect run-time errors that already occur without
interaction between the tasks.
Server
- Under Linux, all files in the server working directory are now created with the default settings for file permissions of the user who started the server.
- Improved registration of the server as a Windows service to ensure a more reliable automatic startup of the server after restarting Windows.
Known issue
When enabling the gauge domain, in rare cases the analyzer may underestimate the value ranges of certain variables. Make sure that the gauge domain is disabled (this is the default setting of the analyzer), or contact support@absint.com for details on scenarios that trigger the undesired behavior.
Side bar



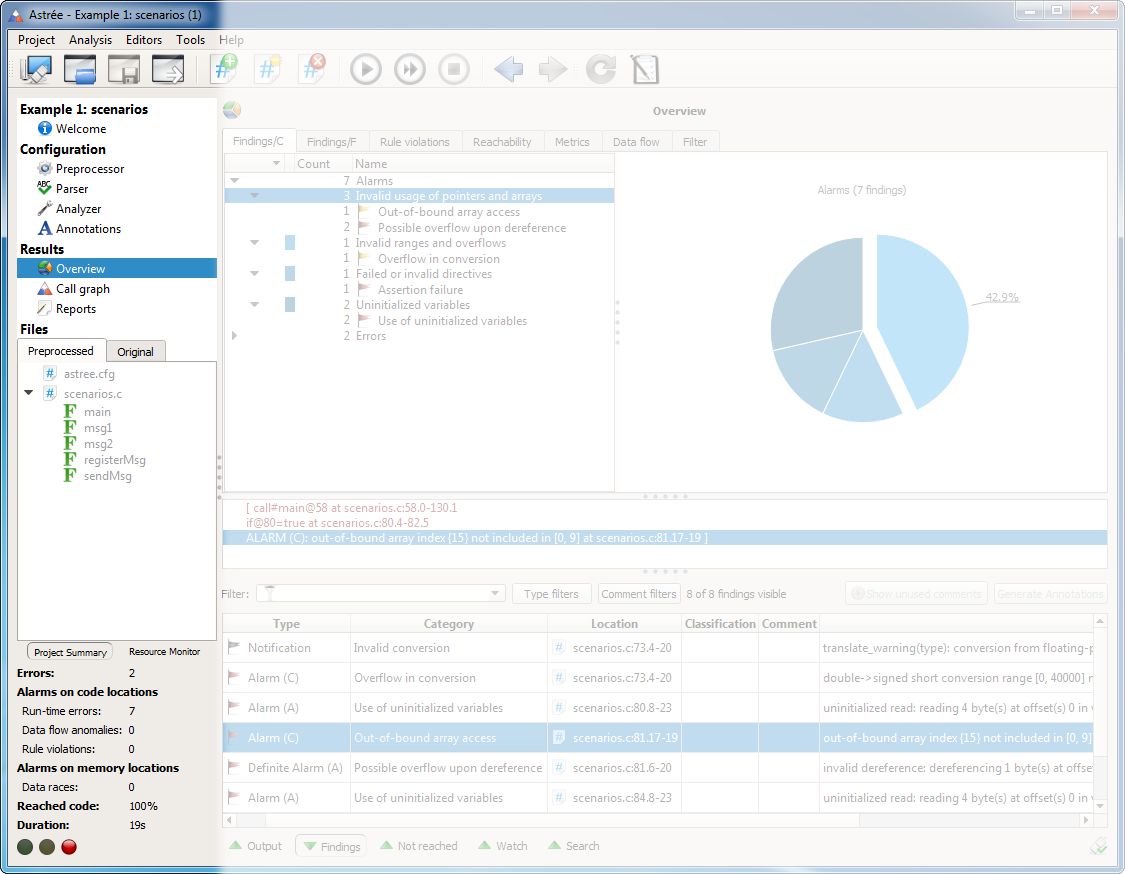
The side bar has improved in a number of ways. The new Results section contains the new Findings view (see below). The new Project Summary area and the Preprocessed Files list provide more information than before. The traffic lights are now displayed horizontally to save space.
Analysis results
- Improved interactive overviews of the results in tabular and graphical form.
- For faster access of individual results, the single button Show results has been replaced by five buttons: Output, Findings, Not reached, Watch, and Search.
- A new Findings view replaces the former Result Viewer. All run-time errors and MISRA-C violations are listed here, and can be classified or commented on. The view can be filtered by various criteria, such as the type of findings or a certain code line selected from the editor view. Thus, this view also replaces the former Line Summary view.
- A new Not Reached view displays all code locations that have not been reached by the analyzer.
- The lists in the Findings and Not Reached views can be filtered in the Results overview and exported as CSV files to create custom reports.
Other GUI changes
- New, highly efficient and scalable display of value ranges
as tooltips for variables in the editor view. The tooltips
are now available even if the export of invariants is disabled
and include more information than before, such as the return values
of function calls. The tooltips are enabled by default
and can be disabled using the new option
tooltips=no. - The editor views for preprocessed and original source code now offer back and forward buttons for fast navigation.
- In the Open Project dialog, analyses that have been marked private by the current user are now indicated by an icon and a remark in the Remark column.
- The verbosity of the output view can now be configured right above the view rather than in the Preferences dialog.
- Improved identifier search now lists all variable definitions (including tentative ones), any intrinsic function calls, and all variables used in Astrée directives and intrinsic function calls.
- Generalized commenting on findings. In the new Findings view, it is now possible to comment on findings for which annotations containing type names are required.
- Comments for findings do not allow newline characters, backslashes, or double quotes.
- In configuration views (ABI, Options, Rules), new context menu entries allow to reset settings to their default values.
- The Annotations view now supports drag&drop for multiple annotations.
Alarms
- An alarm of type D is now raised for each detected definite infinite loop. In older releases this would only issue a notification. For intentionally infinite loops in stub libraries and generated wrapper functions, the alarms can be suppressed using an annotation.
- Messages about failed assertion and check directives are now more verbose.
For example, an assertion of the form
__ASTREE_assert((Y < 27));will raise the following message if the analyzer cannot prove that the specified condition always holds:ALARM (A): assert failure __ASTREE_assert((Y < 27)) at ...
- Reports of erroneous constant expressions now include
an exact description of the error. For example,
a declaration such as
enum { A = 1/0 }now raises the messageALARM (A): division by zero
- New alarms now warn about integer and floating point constants that are too large:
ALARM (C): signed long long integer constant ‘9999999999999999999’ not included in [-9223372036854775808, 9223372036854775807]
ALARM (C): floating-point constant ‘1.79769313488e+308’ not included in 64-bit floating-point range - Data races are now reported as alarms of type B and counted per memory location (i.e., per variable) rather than per code location.
Report files
- The new summary report “Rule checks” documents the Rule Checker configuration
(active rules and checks) together with all violations. It can be generated
in batch mode with the option
--report-rulechecks <filename>or specified in DAX by the element<xml-rulechecks>. - The XML report has changed in the following ways:
- the report is no longer generated on-the-fly, only once the analysis has finished
- the report contains the list of all functions in the analyzed code
- the
<coverage>section now also contains reachability information per function - alarm messages about potential data races also list the involved memory locations (variables)
- Data flow and code metrics report files are now also available in batch mode.
They can be configured by the following command-line options:
--report-dataFlowFunctions <filename>--report-dataFlowVariables <filename>--report-dataFlowProcesses <filename>--report-metricsLocation <filename>--report-metricsType <filename>
- The following information has been added to the Coverage summary:
- how many percent of each function have been analyzed
- the list of the program locations that have not been analyzed
- The differences viewer now provides an “Export to XML…” button
for writing a report file that lists the number of alarms sorted by category
for all compared projects or revisions. The result
is a table of the following form:
Name Description Revision Alarms Division by zero ... my_analysis first 1 2 1 ... my_analysis second 2 49 12 ...
Location information
- Corrected the location information for write-after-write alarms. It now refers to the left-hand-side of the assignment.
- Improved parser error location when encountering unrecognized compiler-specific keywords in declarations.
- Improved location information for alarm messages, in particular for rule violations. It is now more precise, reducing possible overlap between code locations with alarms.
Misc
Astrée now only displays the number of program locations for which alarm and error messages are reported. It no longer displays the number of messages themselves, which can differ from the number of locations (e.g. if analyzing a program location in different call contexts always leads to the same runtime error).
The information about the number of messages has been removed from the Project Summary in the GUI, the XML report, and the XTC result file. This simplification makes the results easier to understand. The omitted information is typically irrelevant in practice.
- Files that could not be found when uploading original source files to the server are now listed in the output view and text report file before starting the analysis.
- The output view and report file now contain separate version information and time stamps for the preprocessing and analysis stages.
- Detailed reachable code statistics per file are now also included
in the text report and output view of the analyzer. Example:
/* Reached functions */ | ------------------------------------------------------------------------ | | | Number of statements | | | Reached functions (5/9) | total | reached | not reached | percent | | ------------------------------------------------------------------------ | | strcpy_x | 5 | 5 | 0 | 100 % | at strcpy_x.c:66.0-72.1 | strcmp_x | 7 | 6 | 1 | 85 % | at strcmp_x.c:66.0-72.1 | malloc_x | 3 | 3 | 0 | 100 % | at malloc_x.c:66.0-72.1 | main | 4 | 4 | 0 | 100 % | at main.c:85.0-91.1 | Proc8 | 14 | 14 | 0 | 100 % | at Proc8.c:66.0-82.1 | ------------------------------------------------------------------------ | /* Not reached functions */ | ------------------------------------------------------------------------ | | | Number of statements | | | Not reached functions (3/9) | total | reached | not reached | percent | | ------------------------------------------------------------------------ | | memcpy_x | 3 | 0 | 3 | 0 % | at memcpy_x.c:67.0-72.1 | Proc3 | 6 | 0 | 6 | 0 % | at Proc3.c:66.0-77.1 | Proc1 | 13 | 0 | 13 | 0 % | at Proc1.c:66.0-88.1 | ------------------------------------------------------------------------ | /* Stubbed functions */ | ------------------------------------------------------------------------ | | | Number of statements | | | Stubbed functions (1/9) | total | reached | not reached | percent | | ------------------------------------------------------------------------ | | Func1 | 4 | 4 | 0 | 100 % | at strcpy_x.c:51.12-17 | ------------------------------------------------------------------------ |
- Notifications and errors are now consistently printed with a “NOTE” or “ERROR” prefix, respectively.
- The different rule checking phases now have dedicated section headers in the analyzer output and text report.
Rule checks
- The New Project wizard now also supports configuring the Rule Checker.
- Simplified configuration of rule checks. The explicit option
rulecheckshas been removed. Instead the Rule Checker is automatically enabled if the set of rules to check for is not empty. The computation of code metrics can now be enabled independently from rule checking using the new optionmetrics=yes. - The new summary report “Rule checks” documents the Rule Checker configuration
(active rules and checks) together with all violations. It can be generated
in batch mode with the option
--report-rulechecks <filename>or specified in DAX by the element<xml-rulechecks>. - New and better frontend for parsing original (non-preprocessed) source files for rule checking. It is more robust and no longer restricts the use of preprocessor directives.
- Descriptive texts for checks and rules, including the official MISRA-C rule descriptions, are now displayed under “Settings” → “Rules” as well as under “Findings” → “Details”.
- With the new option
allow-boolean-constants=yes, the Rule Checker allows0and1constants to be used in boolean contexts. Code likebool_t b = 1;then passes without violation of the MISRA-C:2004 rule 10.1 or the MISRA-C:2012 rule 10.3. - Boolean constants introduced as enumerators are now handled as effectively/essentially boolean (MISRA-C:2004/2012) if they are part of a typedef defining the boolean type.
- Fixed an issue that could cause the Rule Checker to not find the header files of the C stub library and therefore stop with a parse error.
- Fixed check for violations of customer-specific coding rule X.A.5.19.
MISRA-C:2004
- Added support for rule 20.3.
- The underlying type of the
!operator is now always Boolean. - Fixed the reporting of MISRA-C:2004 violations in initializers which caused violations of rule 10.1 to be reported as violations of rule 10.2 and vice versa.
- Fixed false alarms about rule 10.1 and 11.3 in conjunction with null pointer constants and array accesses.
- Fixed false alarms for check
external-file-spreadingfor rule 8.8 related to tentative definitions.
MISRA-C:2012
- Added support for rule D.4.11.
- Added partial support for Directive 4.9.
- Rule 17.3 is now fully supported.
- New option
allow-signed-constant-with-signed=[yes|no]controls whether the essential type model is relaxed, such that constant expressions of essentially signed type and non-negative value that are subject to the usual arithmetic conversions (see ISO/IEC 9899:1999 §6.3.1.8) are considered unsigned, if the other operand is essentially unsigned. - Fixed false alarms about rule 10.3 in conjunction with explicit casts using predefined types and explicit sign information (signed/unsigned char/short/int etc.).
- Fixed false alarms for check
external-file-spreadingfor rule 8.5 related to tentative definitions. - Fixed false alarms about rule 10.4 and 11.4 in conjunction with null pointer constants and array accesses.
Extensions of the DAX format
- Incremented the version number to 1.2.
The ABI specification has been restructured. An example DAX specification is:
<abi import="@ia32.dax" target="my custom abi"> <char_sign>signed</char_sign> </abi>
The base ABI is imported from the file specified in the
importattribute. Any modifications, such as the different value forchar_signin the example above, are listed explicitly. In addition, thetargetattribute can be used to specify a name for the ABI.The base ABI can be imported from any DAX file, not only from the predefined ABIs shipped with the tool. A predefined ABI can be referenced either by its absolute path or by its file name prefixed with an
@, as in the example above, to make the specification installation-independent.The file referenced by the
importattribute must not itself reference another ABI.The
<original-sources>section has been removed. Original source files that shall not be preprocessed by Astrée must now be listed in a<preprocess>section that includes<use-internal-preprocessor>no</use-internal-preprocessor>.Included header files are then retrieved automatically and don’t need to be listed. The
<replacements>and<strip-compilation-path>tags from the<original-sources>section of previous DAX versions are now available within the<preprocess>section. The<strip-compilation-path>tag has been renamed to<strip-path>.- New tag
<private>yes</private>for marking analysis projects as private. When importing a DAX file that uses this tag, the resulting analysis project is marked as private for the user who imported the analysis. Note that this tag must be removed before loading a DAX specification as useranonymous. - When exporting parser settings, the Astrée client now adds
the setting
<pragma-asm>yes</pragma-asm>to the DAX file if filtering of code blocks enclosed by#pragma asmand#pragma endasmwas enabled. - The former top-level tag
<entry>has been replaced by<options> <analysis-entry>function_name</analysis-entry> </options>
- The wrapper and stubs file is now specified as follows:
<options> <config-file>filename</config-file> </options>
The specified file must also be added to the
<files>list.
Updates to the TargetLink coupling
- Added support for TargetLink 4.1.
- Improved the configuration of the Toolbox for TargetLink by separating the preferred server connection settings from other preferences. The server settings are now part of the global configuration and don’t have to be re-entered when using the Toolbox with different models. All other preferences can still be configured on the model level. Additionally, it is now possible to specify a global set of preferences that act as a default in case that no model specific settings are found.
- The new Astrée server settings dialog of the Toolbox provides a dropdown that lists all installed versions of the Astrée client. For each client version, a different server connection can be configured and stored, pointing to an Astrée server that is compatible with the selected client.
- In case of an incorrect server configuration, the generated XTC request can be reloaded to correct the server settings and retry to start the analysis, without having to go back to the Toolbox.
- Semantic support for TargetLink CTO arithmetic is now enabled
by default when the analysis is automatically launched
from the Toolbox
(
exclude-signed-in-unsigned-overflows=yes,exclude-signed-negation-overflows-in-cto=yes). - Bounds for floating point values are no longer rounded to integer numbers by the DD converter.
- The C library stubs are now automatically excluded from the global coverage statistics for analysis projects created by the Toolbox.
- The Toolbox now allows specifying a DAX file for automatic import of analysis configurations.
- Improved API for automating Astrée analyses via M-script.
Configuration
- The internal preprocessor now supports automatic includes
which can be added to each preprocessing configuration.
Files listed as automatic includes are processed as if
they were included at the beginning of each primary source
file in this configuration. In DAX 1.2 automatic includes
can be specified as
<automatic-includes> <automatic-include>string</automatic-include> ... </automatic-includes>
- Preprocessing settings are now shared between clients. Each configuration provides a base path which can be modified in order to quickly adapted the settings to another client.
- Removed options:
warn-on-fullrangedump-process-dataflow
The per-process data flow information is now automatically collected if the optiondataflow=yesis enabled.chrono
For debugging suspected analysis-time issues in analysis projects, contact customer support.export-disambiguate
The export of invariants is now always context-sensitive. Context-insensitive invariants are still available in the new tooltips, which are enabled by default.-uand--files
Automated batch mode analyses can be fully configured by DAX files.
- Options now enabled by default:
dataflowauto-generate-stubscase-insensitive
__ASTREE_initialize((v))now has an effect whenvis an array or a structure. It initializes the whole array (or structure), and in addition removesNaNand infinities from floating point values when using the optionkeep-float-specials=no.__ASTREE_modify((v; full_range))now also setsvto be initialized when it is an array or a structure. In such cases, it doesn’t addNaNand infinities anymore when using the optionkeep-float-specials=no.- OIL files for OSEK configuration specified in the preprocessing view are now uploaded to the analysis server where they appear in the list of original source files.
- Fixed an issue in the ABI settings view of the GUI that prevented the modification of pointer sizes.
- Nested preprocessing configurations now correctly inherit include paths and macro definitions from their parents.
- Fixed an issue that prevented the commenting of alarms from the
Wrapper and Stubs view if the wrapper contained an
__ASTREE_import(())directive. - Added a GUI preference that controls whether report files are automatically updated after an analysis run.
The synchronous execution model of Astrée supports an upper bound for the effectively maximal iteration count of infinite loops, to be used for the cyclic executive loop. The bound becomes effective when using the directive
__ASTREE_wait_for_clock(()).In previous releases, the analysis entry functions generated by the wrapper generator and the TargetLink importer made use of
__ASTREE_wait_for_clock(())to bound the maximum execution steps of the generated main loop. For the sake of clarity this default has been changed so that no upper bound for the maximum number of execution steps is implicitly assumed.Both the wrapper generator and the TargetLink importer provide a new option so that users can explicitly activate a maximum loop bound with a user-specified value. The bounds can also be specified via DAX by the new
<max-clock>tag inside the<wrapper>or<data-dictionary>tag.- The syntax of suppress-source directives has been extended
to allow to cover the remainder of a file
by omitting the length argument. For example,
the following directive suppresses all rule checks for a source
file when inserted in the first line of said file:
/* ASTREE_suppress(0, , rules-category) */
- The intrinsic
__astree_create_processaccepts a name as optional last argument. That name is printed in the output window and in the call graph and data flow view when referring to that process.
Authentication
- Users can now change their passwords from within the client GUI via “Project” → “Change password...”.
- Optionally, the client can now remember the user and password
for a server connection. In this configuration it is possible
to run the qualification support kit (QSK) even if the user
anonymoushas been disabled by the server administrator. - Authentication information provided via
the option
--user username@passwordcan now be stored by using the new option--remember-password. Subsequent connections, whether in batch mode or via the GUI, then automatically re-use the stored authentication information unless different information is explicitly provided.
Analysis history
- Multiple revisions of a project can now also be compared by selecting them in the Open dialog, right-clicking and invoking Compare from the context menu. It is no longer necessary to first open the analysis history graph.
- The analysis history can now be accessed via the Project menu. The entry “Project” → “History” → “Show revisions…” opens the history graph to display the currently existing revisions. The entry “Project” → “History” → “Create new revision” creates a new revision based on the currently opened revision. The new revision is automatically opened.
Patch 1 (build 264466)
- Fixed rule checking to prevent rule violations for source files
contained in the “List of source files to exclude from rule checks”
(option
ignored-source-files). - Fixed unfinished AAL conversion of comments and possible server crash when the client disconnected during the conversion.
- Fixed error reporting of the original-sources parser so that it points straight to the corresponding line in the source code if possible.
- Fixed the interpretation of macros that are passed on the command line
(e.g.
-DFOO=bar) in the original-sources parser used for rule checking. - Fixed a regression where settings imported via DAX reset existing settings.
- Fixed the parallel analysis mode to consider the
__ASTREE_max_clockdirective. - Fixed wrong highlighting of messages and not analyzed code in the editors for original source.
- Fixed a file handling issue that could cause certain files to be reported as unknown or not found during parsing.
- Improved fallback for generating AAL paths to prevent losing alarm comments.
- Optimized the
partition-array-accessheuristic to reduce the memory consumption and analysis time on certain code. __ASTREE_commentdirectives that specify the type of alarm to comment on now only affect alarm messages for exactly the specified code range.__ASTREE_commentdirectives without an alarm type behave as before, affecting all alarm messages anywhere within the specified code range. This modification enables precise commenting on nested alarms of the same type in the Findings view.- The wrapper file is no longer subject to MISRA rule checks.
Patch 2 (build 265481)
- Fixed the XML report generation in batch mode to output the correct
comment_kindattribute for commented alarm messages rather thanundecided. - Optimized loading the Findings view for findings with a large number of contexts.
- Previous versions of the analyzer might stop with the message
“NOTE: Direct flow changed to ⊥ during test in this context”
after encountering a comparison that involves a variable with a range strictly
right or strictly left of zero:
if (...) x = 1.; else x = -1.; y = x == 0.;
This issue has now been fixed. In older versions of release 16.04, it can be worked around by using the optionfloat-distance-to-zero=no. - Fixed AAL generation for program locations after labels.
E.g., when generating paths like “case A: + N statements”,
the value of
Nin the generated annotation was off by one. - New command line option
--preprocess-report-file <file>for writing a plain text file that contains the preprocessor output as displayed in the Preprocess view. The option is particularly useful for observing the progress of the preprocessing phase in batch mode. - The
indentation-levelrule check is now run before parser filters on original code. This fixes the customer-specific rule X.A.4.8 in the presence of parser filters applied to line beginnings. - Fixed rule check
cast-implicitto not warn about implicit casts on pointers that only concern type qualifiers. The check is used in customer-specific rule X.A.5.44.
Patch 3 (build 265552)
Fixed false alarm about customer-specific rule X.A.4.8 that was raised for a multi-line comment when the last non-newline character before the comment was a slash.
{kind=link}
{kind=link}