- Red Hat Enterprise 5 is no longer supported. The minimum requirement is now Red Hat Enterprise 6 (CentOS 6) or compatible distributions.
- In addition to the installer that requires administrator rights, a³ is now also available as a simple ZIP archive that can be unpacked and used without installation.
- Improved support for displays with high dpi values.
- The Safety Manual now also addresses a³’s relation to the IEC-61508 and Cenelec EN-50128 safety standards.
Targets
- aiT for TriCore now supports AURIX TC275 (TC1.6E and TC1.6P).
- aiT for C16x now supports XC2365A-104F80L.
- TimingProfiler is now available for ARM (Cortex-M and Cortex-R), LEON2 and LEON3.
- a³ for TriCore now supports the Diab compiler.
- StackAnalyzer and ValueAnalyzer are now available for MCS 51 (TI CC254x) with the IAR compiler.
- A compiler-specific Qualification Support Kit is now available for StackAnalyzer for x86 with GCC 4.9.2.
Integration with TargetLink
Improved handling of optimization binaries in conjunction with automatic annotation extraction from the Data Dictionary.
GUI
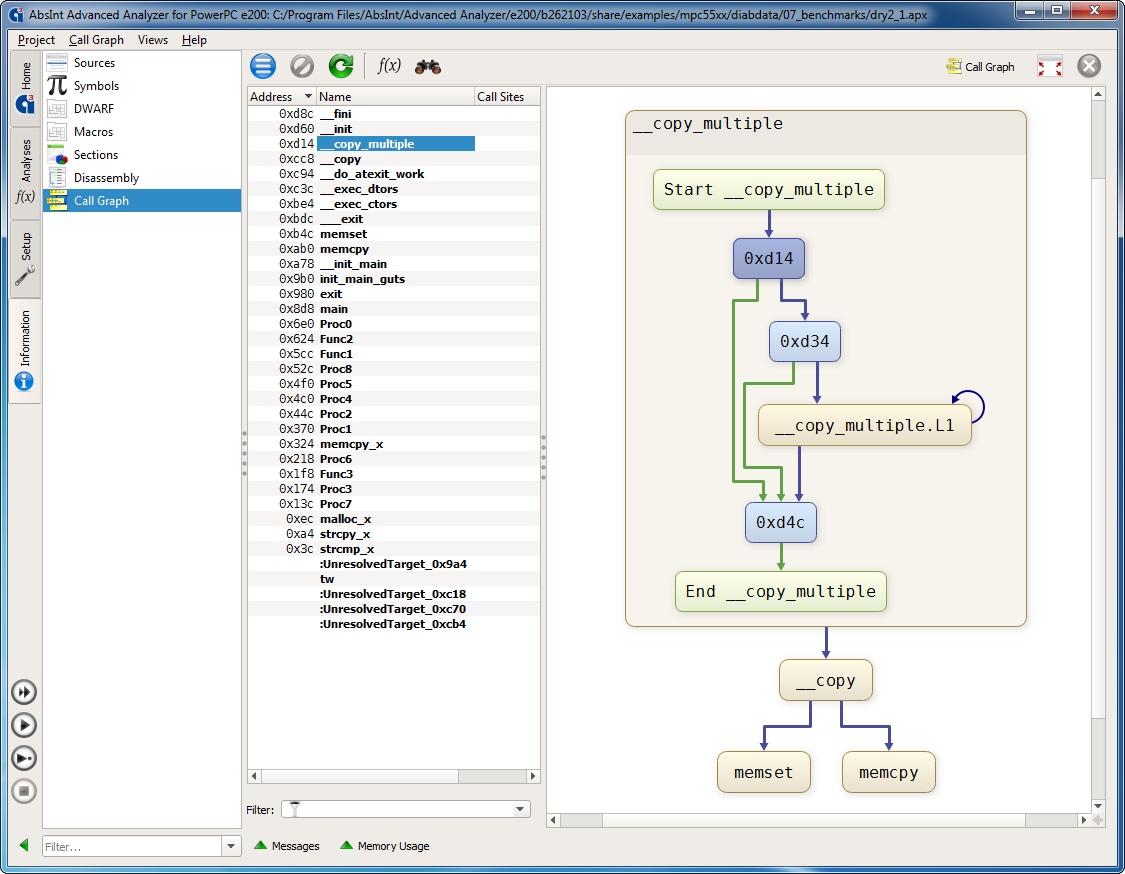
- Two all-new information views Disassembly and Call Graph allow to disassemble the complete binary at once and generate call graphs for any functions.
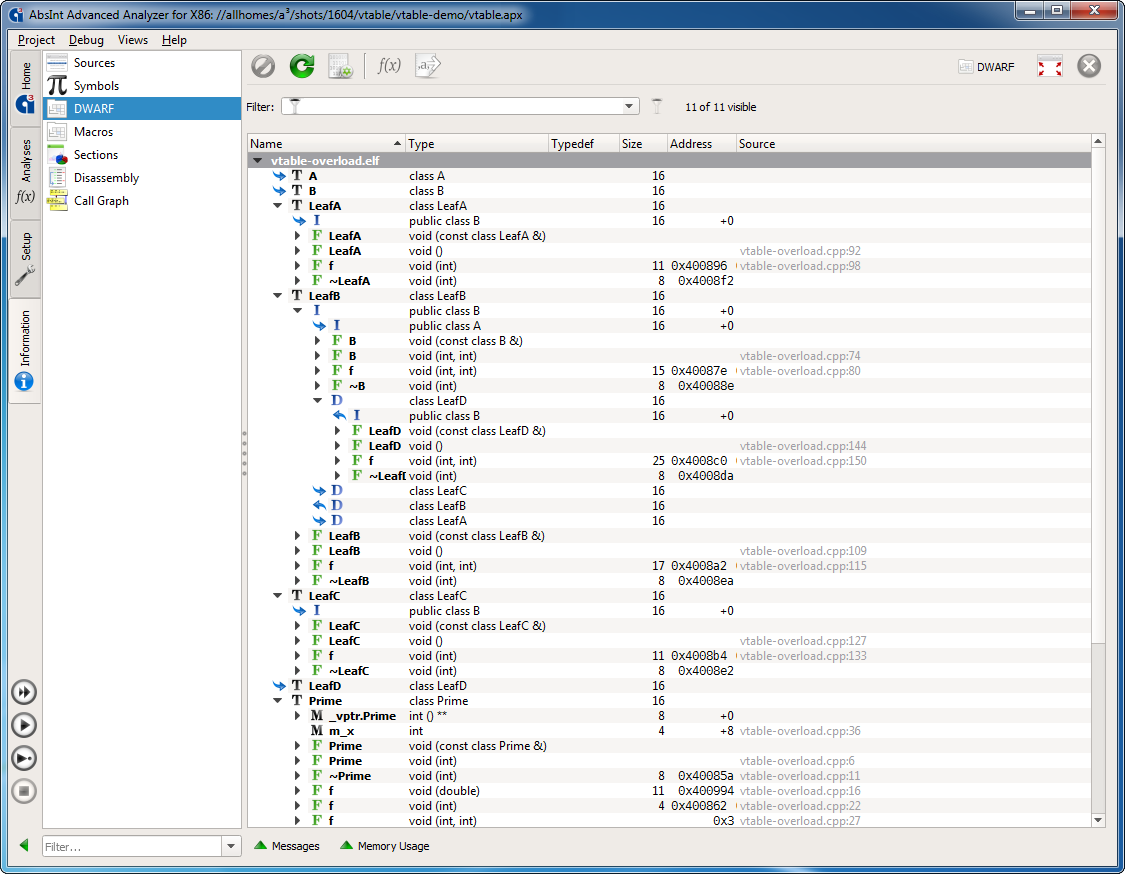
- The DWARF view has been extended to also show:

- information about function-local variables and the scopes they reside in
- information about structure and class types that contain static member variables
- union/struct/class inheritance
- It is now possible to jump to the DWARF view from context menus of messages, interactive value analysis results, and several other places.
- The Source Code view now shows both the source and target of an annotation.
- Likewise, annotation icons have been updated to indicate both the source and target of the annotations.
- Analysis comments can now be edited in a multi-line text editor.
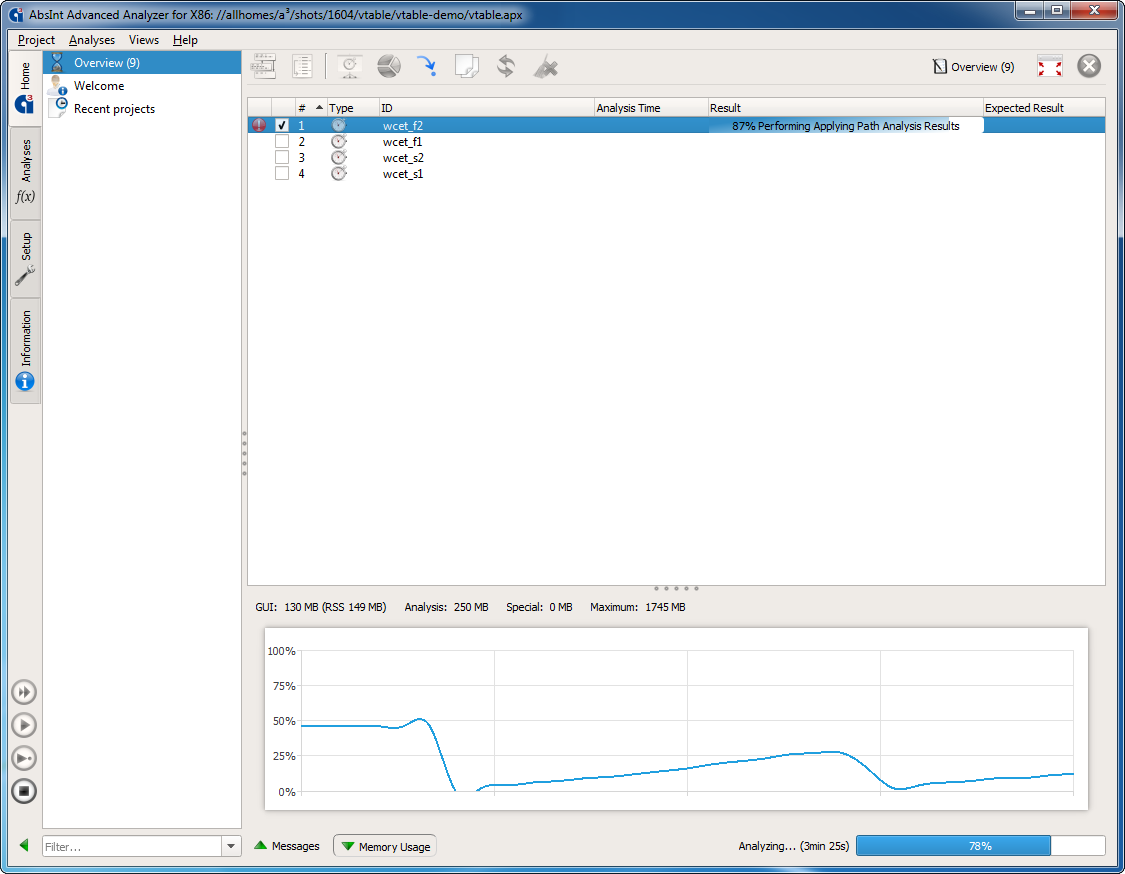
- The memory usage can now be monitored in a dedicated view.
- Improved ResultCombinator:
- ResultCombinator can now be started and run even if dependent analyses are disabled
- you can now choose whether the calculation should use existing results, or initiate new analysis runs
- additionally, the result of the calculation is shown in the message window
- The Create Support Archive dialog now supports easy filtering of the files to be included in the archive.
- Improved GUI performance for projects with many analyses.
- ORTI files (OSEK/AUTOSAR) can now be imported to generate an a³ project file with analyses for the individual tasks.

AIS2
AIS2 now officially replaces AIS1.
The second revision of the AIS annotation language comes with many new features and is much more user-friendly. For backwards compatibility, AIS1 specifications are still supported and included in the appendix of the user manual.
We strongly recommend upgrading your analysis specifications to the new AIS2 format.
Key improvements and new features are explained in the notes for release 15.04 and 15.10. New features in this release are as follows.
- It is now possible to collect values from initialization
routines automatically, for example:
collect initialization: "msg_length", "can_msg_buffer";
- The
assert assemblyannotation now supports regular expressions:ais2 { instruction <pp> assert assembly: match("bkpt #[34]"); } - Annotations can be guarded to only have an effect
in certain circumstances, notably for a specific kind of analysis:
# unroll loops 16 times for non-stack analyses if (!analysisType("stack_analysis")) { mapping default unroll: 16; } - AIS2 supports
enter withannotations for calls between two routines. This is helpful when the value annotation depends on the calling context which cannot be easily expressed with a routine-specific enter annotation:ais2 { routine "handleInput" calls to "memcpy" { enter with: reg("r5") = 80; } routine "handleOutput" calls to "memcpy" { enter with: reg("r5") = 40; } } - Call paths can be excluded using the new
infeasible call stackannotation:# specify that QuickSort cannot be reached from f->QuickSort->QuickSort routine "QuickSort" { infeasible call stack: "f", "QuickSort", "QuickSort"; } - The annotation to count accesses to global memory regions
can now be specified for multiple disjoint memory regions:
ais2 { area 0x0 to 0xffff, 0x40000000, 0x4000fff { count accesses; } }This instructs the analysis to count accesses to either0x0..0xffffor0x40000000..0x4000ffffon the WCET path. - AIS2 annotations to resolve computed calls via class inheritance information.
For example, consider the following C++ code:
class BaseButton { public: virtual ~BaseButton () { } public: virtual void clicked () = 0; }; class SingleButton : public BaseButton { public: void clicked () { // do something } }; class SingleButtonWithIcon : public SingleButton { public: void clicked () { // do something else } }; void handleButton (class BaseButton *button) { button->clicked (); }The compiler cannot statically determine which member function is going to be called when executing the function
handleButton. Instead it generates code to look up the correct member function based on the virtual function table of the corresponding object instance.You can use the following annotation to enable the decoder to resolve the computed call:
instruction "handleButton" -> computed (1) calls: "BaseButton"::"clicked";
The decoder will then resolve the call to the member function implementations
SingleButton::clickedandSingleButtonWithIcon::clicked. - AIS2 allows resolving via inherited union/struct/class members.
- Improved handling of AIS2 complex area annotations when resolving pointers that target inside arrays.
- Improved parsing of source files for extracting AIS annotations. No warnings are issued about unknown escape sequences outside of annotations.
The complex area definition now offers the attribute
skipped: type;for checking whether the pointer target has the expected type. The attribute is similar to theskipped: null;attribute.Consider the following C snippet:
typedef void (*fPtr) (int); void f (int x) { ... } void g (int x) { ... } struct fEntry { fPtr x; int y; }; struct fEntryLarge { fPtr x; int y; int z; }; const struct fEntry a = { &f, 3 }; const struct fEntryLarge b = { &g, 5, 12 }; const struct fEntry *fTable[2] = { &a, &b };The complex area definition
("fTable"[]->"f"->)would evaluate to the addresses of the routines
fandg. However, according to the declaration offTable, it should only contain pointers to structures of typefEntry. Nonetheless, C compilers often allow the above code even thoughaandbare in fact incompatible types.In order to check whether resolved addresses refer to objects of expected type, you can now use the following definition:
("fTable"[]-> { skipped: type; } "f"->)Using debug information, the decoder only resolves the address of
fand ignores the second table entry offTable. In this case, it will report:Discarded pointer targets with unexpected type.
Expected type ‘const struct fEntry’, but found ‘const struct fEntryLarge’ at 0x4005f0.
Decoding
- Improved handling of section relocations.
- Decoding supports executables created by multiple compilers
(e.g. GCC and GNAT). The decoder will provide a hint which compilers are applicable:
exec2crl: Fatal: Compiler is ambiguous, please use a compiler annotation to specify the matching one. Possible compilers are: 'Greenhills C compiler' (ppc-greenhills), 'Greenhills Ada compiler' (ppc-greenhills-ada)
- Extended DWARF debug information reader to support range lists.
- Improved heuristics for function names to prefer nice DWARF names.
- Improved heuristics to resolve computed call tables using DWARF debug information.
- Improved file type detection for Intel HEX files.
- ARM:
- support for the instructions
sdivandudiv - improved handling of the THUMB instructions
bfcandbfi - improved decoding of switch and call tables for GHS
- improved stack pointer guessing for IAR
- support for the instructions
- C16x:
- improved switch table pattern resolution for Tasking VX
- improved automatic decoding of computed calls via symbol table
- C28x: added support for FPU and VCU-I/II instruction set.
- HCS12: it is required to specify the address format for the DWARF information, surface or linear addresses, to ensure the correct address information can be read out.
- PowerPC:
- improved detection of pseudo calls to get the PC value
- improved resolving of computed calls
- TriCore: improved decoding of
- switch tables
- call tables
- computed calls that cross the 24-bit memory boundary
- code-size optimized binaries
- V850: improved stack pointer guessing for IAR.
Stack and value analysis
- Stack analysis and value analysis for C16x, C33, and HCS12 have been ported to the new EVA value analysis framework. This entails changes in analysis behavior and precision, as described in detail in the notes for release 14.10.
StackAnalyzer can now be run in context-sensitive mode, allowing the analysis to rule out transitions that are infeasible in the context-sensitive call graph.
This is especially useful for deeply nested call stacks, where context-sensitive analysis gets much more precise results.
The GUI now offers three analysis modes:
- Optimized stack analysis without worst-case path information at routines (context-sensitive)
- Optimized stack analysis without worst-case path information at routines (context-insensitive)
- Stack analysis with worst-case path information at routines (context-insensitive)
Context-sensitive analysis is the default, as it is the most precise.
- For improved clarity, StackAnalyzer no longer computes lower bounds.
- Some default values have changed.
- The default “Size limit for interval sets” has been increased from 1 to 16. The new default allows for better resolution of computed calls. The value can be decreased when faster analysis is needed.
- The default “Value analysis widening delay” has been decreased from 16 to 4. This will speed up the analysis at a slight cost to precision. The value can be increased when higher precision is needed.
- Imprecise stack effects inside a loop are now reported in the Message view:
#3081: Propagating a non-zero system stack effect for loop 'task_handler_1ms.L1'. Current relative system stack height is [64..128] bytes.
- The stack and value analysis now use incarnation limits to make contexts infeasible.
- More precise value analysis by better preservation of relational information.
- Improved precision of:
- branch splitting
- memory access restrictions via DWARF debug information about arrays
- calling convention application for subregisters
- annotations affecting the stack analysis for function calls
- the relational domain if the relations are complex, e.g. contain typecasts
- bit-wise operations such as PowerPC’s
rlwinm - value analysis of loops with short callstring settings
- value analysis for compares like
x <> x + y
- Improved handling of:
- shift loops
- 8-bit and 16-bit loop counter values
(x % 2) == 0code patterns- “never returns” routines, avoiding false warnings about not obeyed calling conventions and the like
- StackAnalyzer will report the maximum call stacks
made infeasible by exceeded incarnation limits during
path enumeration:
*** *** Maximum stack usage for entrypoint 'main' *** Maximum global usage: 96 bytes of stack => Callstack for maximum global usage: -> 0 < 48> 'main' -> 48 < 12> 'fib' -> 60 < 12> 'fib' -> 72 < 12> 'fib' -> 84 < 12> 'fib' => 96 bytes of stack Applied incarnation limits: => Routine 'fib': 0: main -> 1: fib -> 2: fib -> 3: fib -> 4: fib -> 5: fib <= infeasible because of exceeded limit - Improved XML loop bound statistics.
- Improved warning for writes to read-only memory area when the area
is related to a stack pointer register:
eva-microblaze: Warning #3075: In "minmax.c", line 17:
In routine 'max', at address 0x20c:
In context '0x2bc->"max"':
Write access related to stack pointer 'r1' to [0x000004df]:4, which overlaps with read-only memory. - Improved application of calling conventions for relational domains.
- Local loop unrolling settings are now included in the reports:
eva-hcs12: Info: Local default-unroll settings for loops:
* Loop 'main.L1' default-unroll = 256 ('stack modification' heuristic)
* Loop 'main.L1' default-unroll = 10 (annotation)
* Loop 'CASE_SEARCH_8.L1' default-unroll = 256 ('switch table' heuristic) - ARM: improved handling of STREX instructions.
- C28x: added support for FPU and VCU-I/II instruction set.
- HCS12 and MCS51: EVA will auto-unroll most compiler generated stack modifying loops.
- PowerPC:
- improved precision for the
rlwinminstruction - improved handling of byte reversed memory access instructions
- improved precision for the
- TriCore: improved precision of
muls/muls.uinstructions.
Cache and pipeline analysis
- Faster pipeline analysis for tasks with computed calls with many targets.
- MPC55xx: improved pipeline model.
- Cortex-R5F: improved pipeline model for TI TMS570 LC 4357.
- e300/MPC7448/MPC7448s/MPC755/MPC755s/PPC750:
added support for
twandtwiinstructions, which are now handled as computed calls and executed as integer instructions. - MPC7448/MPC7448s: improved LSU clash checking by skipping comparison against eieio/sync instructions. This prevents false warnings about missing memory access timings.
Path analysis
Cumulative WCET computation has been improved and is now feasible in more cases.
Visualization
- Infeasible edges in the call graph are now colored light gray.
- Graph search now supports:
- search for the addresses of memory accesses for value and timing analyses
- search in selection
- Export of graphs is now faster and consumes less memory.
Reporting
- exec2crl now outputs information about read binaries, including MD5 sums:
exec2crl: Info: Reading binary 'edn.elf'.
* Type: ELF
* Size: 519 KB (532246 bytes)
* MD5: f9edb23a7168d993451073fabdbab1fa - StackAnalyzer now writes the call stack for maximum global usage to the HTML report.
- More consistent output of analysis context for messages:
eva-ppc: error #3076: in "test.c":
In routine 'test2.L2', at address 0x4594:
In context '0x4938->"test1", 0x4710->"test2", 0x4578->"test2.L1"[2..]':
User annotated loop bound of [8] contradicts computed loop bound of [1].
Annotating a loop bound of [0], which may lead to an incorrect analysis result.