
New targets
- aiT for e200 now supports SPC58NE84 and SPC58NN84.

- aiT for TriCore now supports TC277.
- aiT for ARM now supports ARM7TDMI and Sharp LH79520 (ARM720T).

- StackAnalyzer and ValueAnalyzer for x86 now support 64-bit x86s.
- A generic TimingProfiler is now available for all targets supported by StackAnalyzer and ValueAnalyzer.

Greatly improved performance
The analysis speed and memory consumption have been improved by streamlining the analysis toolchain and reducing the number of required tool runs. Extreme speedups can now be achieved, especially on projects with a large main analysis and many smaller subanalyses.
Qualification Support Kits
- New compiler-specific QSK for StackAnalyzer for PowerPC with GCC 4.3.3.
- Additional test cases for StackAnalyzer for PowerPC with GCC 4.1.2.
- New test cases for:
- routine-local increase of call string length
- recursive routine-local increase of default unroll
- marking targets of a computed call infeasible
- propagated stack effect on not-analyzed code that is declared to obey calling conventions
- bound annotations of irreducible recursions and loops
- the new GUI option “Use legacy AIS annotations”
- 26 new test cases for ResultCombinator.
- Consistency checks for XML result and XML report files.
- Additional tool run for checking the AIS2 entries operator within
qk_ais2_expression_pp_areaoperators. - Requirement identifiers in the reports are now prefixed with
REQ_to better distinguish them from test case identifiers. - Tool run execution is now done by calling alauncher rather than the a³ GUI.
Linux support
The Linux version now requires the libxcb-* family of libraries to be installed.
Integrated context-sensitive help

You can now simply press F1 to get context-sensitive help for the current screen, a selected keyword, or a highlighted message. The previously separate quick references for graphs and AIS are now integrated in this help as well.
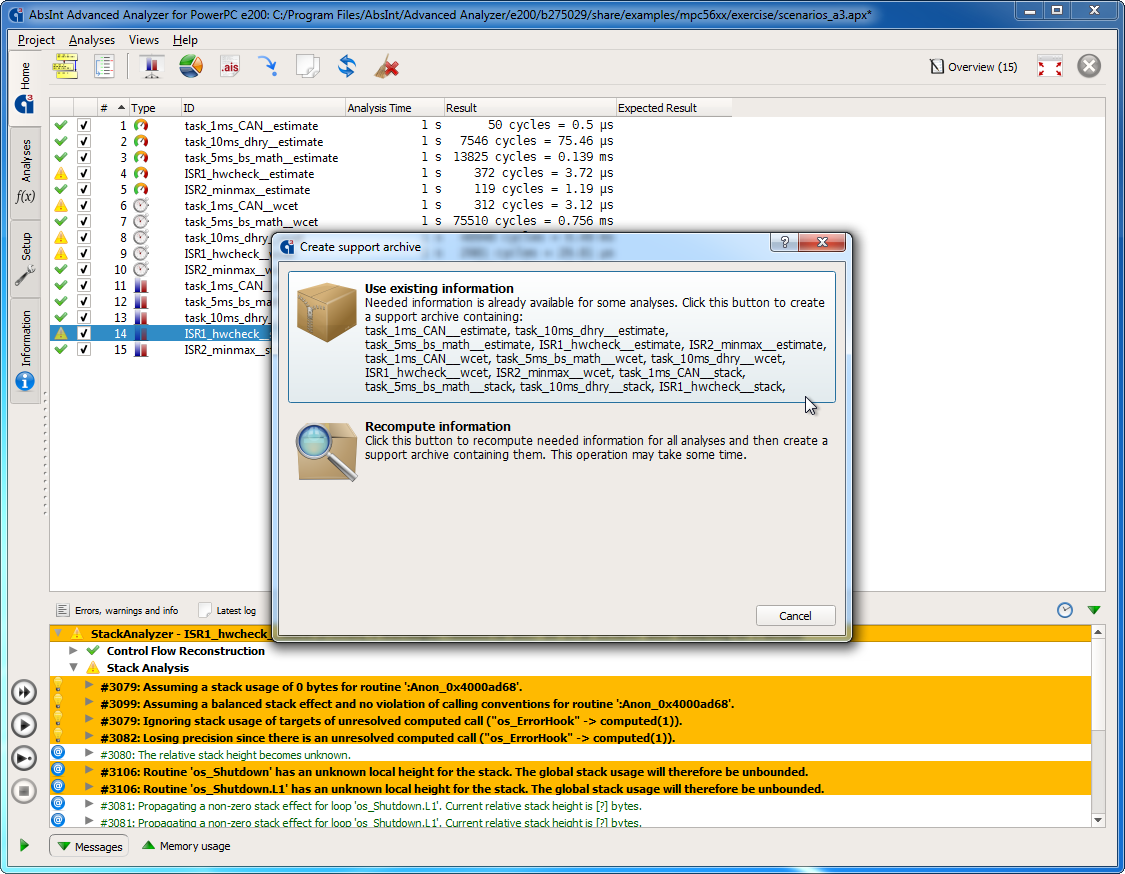
Support archives
In addition to packing the complete project as before, you can now choose to only pack the most recent analysis run. This is very fast, as no recomputations are needed.
Workspaces

- Improved open/save performance.
- Additional information is now kept when saving a Workspace, such as the current folding state of the analysis list.
Overhauled examples
The provided example projects have been improved to showcase more analysis features.
Other improvements
- In the project tree, all open AIS files of a particular analysis are now grouped together.
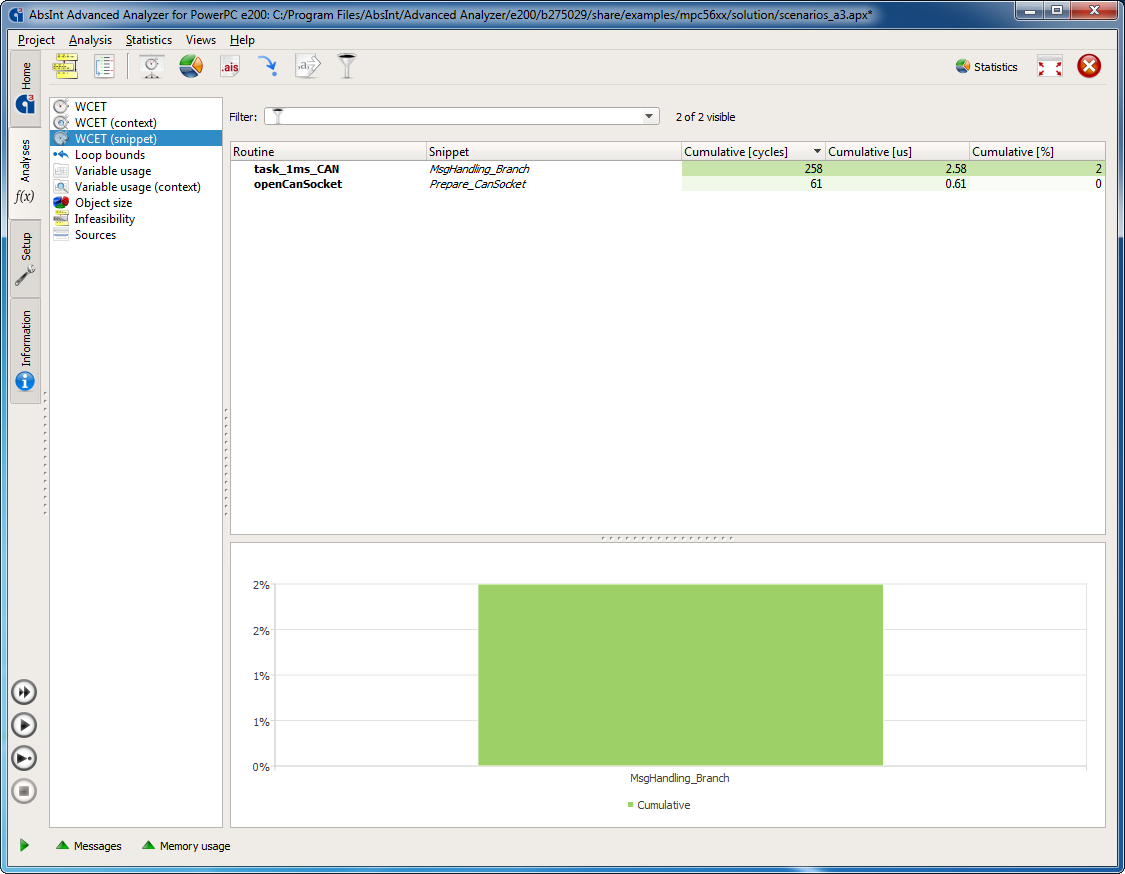
- The Statistics view now includes the (cumulative) contribution of WCET snippets
from
evaluated .. asannotations. - Improved Memory Usage view: the exact memory consumption is now shown in a tooltip under the mouse cursor.
- ORTI import will not handle
_FuncTaskandFuncTaskas duplicated entries and choose one of them. - Improved handling of source files with relative paths.
- Configuration widgets can now be reset to their original state from the context menu.
- Support for multiple data dictionaries.
- Support for drag&dropping a³ project files.
- Improved performance for projects with many analysis items.
- Include paths in the Settings → Sources view are adjusted like other file names when the project is saved.
- In batch mode, the tool now exits with a failure code if invalid (enabled) analysis items have been found.
AIS2
- You can now increase the call string length for individual routines:
# short global callstring mapping max length: 1; # longer local callstrings routine "Func2" { mapping max length: 2; } routine "Proc1" { mapping max length: inf; } - You can now set the unrolling for individual recursive routines:
# local unrolling routine "fac" { mapping default unroll: 2; } - External routines, e.g. trap routines à la "syscall_3",
can now be annotated using the match functor:
routine match("syscall_(.*)") { obeys calling conventions; stack "user" usage: 0 bytes; stack "system" usage: 64 bytes; } - Improved handling of "end" annotations in conditional annotation scopes.
- New AIS2 expression to determine the number of entries in an array. Given the C array declaration
static int dataTable[124];
the number of entries in the arraydataTablecan be accessed as:entries("dataTable")This can then be used, for example, to bound a loop that iterates over that array:loop "processData.L1" bound: entries("dataTable");
Decoding
- DWARF debug information now supports C++ namespaces, template classes and template functions.

- The decoder now reports more precisely what information it is reading
from writable data sections to reconstruct the control flow:
Reading 4 bytes (0x204) at address 0x24a8 (variable 'arr[1]') from writable section '.data' to reconstruct the control flow.
You should manually verify the reconstructed control flow.
Potentially you might need to annotate branch/call targets. - Improved switch and call pattern resolving by taking the calling conventions into account.
Function-local static variables can now be addressed in AIS2 by means of DWARF debug information. To avoid conflicts with global variables, the name of the enclosing function is prefixed.
As and example, consider the following source code snippet:
void handle_msg (...) { static int buffer[128]; ... }The local static variable
buffercan then be addressed viahandle_msg::buffer.- The decoder now reports if user-provided contents of memory regions are located in volatile memory.
- Improved handling of WindRiver code factoring optimization.
- Improved stack pointer guessing.
- Improved iterative decoding performance by not querying stack pointer related register values.
- Message #1050 is now classified as a warning:
Loop <function.Lx> is specified in AIS as type 'end', but might rather be a 'begin' loop.
- ARM:
- Improved decoding of switch tables.

- Improved handling of compiler library code.
- Improved decoding of computed calls via trampoline routines.
- Improved classification of instructions as call or branch.
- Improved handling of symbols/DWARF entries that have the THUMB instruction set bit set. Now correctly clamped to the next lower address to make them usable for AIS annotations.
- C16x: improved DWARF debug info extraction for the Tasking VX compiler.
- C28x: for the TI compiler, the .econst section is automatically marked as read-only.
- PowerPC:
- Improved automatic decoding of computed calls via multiple levels of pointer indirections.
- Improved handling of decoding if multiple binaries are used on VxWorks. slTable jumptable content is guessed based on matching of trampoline call function names.
- Improved stack analysis for CodeWarrior.
- SPARC: Improved automatic switch table pattern decoding.
- SuperH: Improved automatic decoding of computed control-flow.
- TriCore:

- Improved CSA base guessing.
- Improved automatic decoding of computed calls via multiple levels of pointer indirections.
- Improved automatic decoding of switch and call tables.
- V850:
- GHS: Improved ROM small data area pointer guessing.
- Improved automatic decoding of switch and call tables.
- Improved automatic decoding of computed calls via multiple levels of pointer indirections.
- Improved automatic decoding of switch tables via iterative decoding.
- Improved assembly string output of instructions with shifted immediate constants.
- Generally improved decoding of computed calls. Better automatic decoding of computed call tables.
Analysis settings
- New option “Use legacy AIS annotations” (under Setup → Decoding).
The default is
falsefor new projects,truefor old ones. When the option is disabled, all AIS files will be parsed as AIS2, allowing to use AIS2 annotations freely without theais2scope and disabling the legacy AIS1 annotations. - The default for “Assume aligned data accesses” has been changed to
false. - ARM: the new default target is now “Generic ARMv7” rather than ”Generic ARMv5“.
- e200: core-local IMEM and DMEM base addresses can now be configured.
Stack and value analysis
- Improved analysis speed and memory usage.
- Higher precision for:
- 64-bit multiplication
- loop bound computation
- XOR operations used to compare two operands
- short call string lengths
- calls of mixed types (e.g. normal and tail) to same routine
- Improved loop analysis for:
- loops with complex counter updates
- loops with modulo computations
- multi-exit loops
- Improved heuristics based on DWARF debug information.
- When the option “Use DWARF debug information to restrict memory accesses” is enabled,
in addition to the sharpening of the accesses it will now try to derive loop bounds.
In reports, such bounds will be marked as heuristic matches:
Loop 'memcpy.L2': heuristic matches in all contexts with [2..17] iterations (loop is assumed to iterate over array(s) 'buffer')
- Improved initialization analysis for:
- writes to sets of adresses
- architectures with paging
- Improved performance of value analysis for larger “Size limit for value sets” values.
- Improved fixed-point iteration performance. This may reduce precision, which can be countered by increasing
default-unroll,max-length, or the widening delay. - Improved relational domain for XOR relations.
- Better sharpening of the interval domain.
- Unrealistic loop bounds (greater than 220) that are caused by analysis artifacts are discarded by the analyzer.
- Improved loop bound and value analysis in context of array accesses.
- Use loop analysis information to improve DWARF array heuristic access sharpening.
- MCS51: improved handling of the ACALL, LCALL and RET instructions.
MSP430: added a heuristic that changes the default unroll parameter to 32 for repeat loops.
For example, given the repeat loop
rpt r7: addx.w r9, r12
the analysis will change the local default-unroll settings for the loop and report the change as:
eva-msp430: Info: Local default-unroll settings for loops:
* Loop 'main.L3' default-unroll = 32 ('repeat loop' heuristic)- SuperH: improved handling of FPSCR FPU register in value analysis.
- TriCore: introducing a more consistent stack naming, “stack” and “csa” instead of “user” and “system”. Old annotations are still valid.
- V850: improved precision of
macandmacuinstructions.
Cache and pipeline analysis
- e200: improved precision.
- PowerPC: improved handling of synchronization instructions.
- e300/MPC755/MPC755s/PPC750:
- code-duplication support
- improved arbitration between data cache and normal read/store instructions in LSU/BU
- i386: improved chipset simulation in pipelined bus mode.
- XMC4500:
- improved handling of speculative fetches
- initial PSRAM read accesses are delayed by an additional cycle
Path analysis
- Irreducible recursions can now be bound, quite similarly to reducible recursions, using the syntax
routine "test" { recursion bound: 0 .. <int>; }If no annotation is given, the default recursion bound is used. The path analysis phase will write to the report files how this bound is applied.poptimize2ilp: info: in "test.c", line 16:
In routine 'f', at address 0x2000:
Applying recursion bound of 4 to irreducible recursion 'f' comprising the routines:
* f
* g
* h
Calls from the following routines are considered recursion entries:
* main - Irreducible loops within a routine or loop can be bound with
routine "test" { irreducible bound: 0 .. <int>; }If no annotation is given, the default loop bound will be used. If you need to prevent that from happening, simply set the bound toinf:routine "test" { irreducible bound: inf; }
Reports
- The
suppress messageannotation now also suppresses the message in HTML/XML report files. - Failed expected results are now included in HTML reports.
- XML result files now include:
- the number of decoding rounds
- the maximum memory usage in MB (new attribute
analysis_maximum_memory)
- Reports for additional-start analyses now only mention routines reachable from the corresponding additional start.
Messages
- More messages now have numbers, so that they can be suppressed locally or globally.
- The value analysis now only emits message #3081 about propagating a stack effect if the effect in question has an imprecise value.
- The error message about unresolved conditional branches is avoided if the branch is guaranteed to not be taken.
- Value analysis will now propose “collect <var>” annotations for a separate
init analysis to resolve computed control flow:
Info #3156: Annotation hints for init analysis to resolve computed control flow.
ais2 { # unresolved computed call ("report_fatal_error" -> computed(1)) collect initialization: "fatal_error_handler"; # unresolved computed call ("get_current_time" -> computed(1)) collect initialization: "get_tick_timer_handler"; } - More accurate wording of message #3079 for a not-analyzed routine
that is annotated as having a stack effect but no stack usage. Example:
routine "min" { not analyzed; stack effect: 555 bytes; }The new message now reads:#3079: Assuming a stack usage of [0..555] bytes for routine 'min'.
The old message would simply say “0 bytes” instead, not accurately reflecting
the values the analysis was actually working with.
For external and not analyzed routines, when the analyzer assumes that calling conventions are obeyed, it now also assumes a balanced stack effect. The effect is deduced from the calling instruction.
For TriCore, the effect of a
retinstruction is simulated if no propercall*,fcall*.jl*,syscall,trapvortrapsvhas been used to call the external (or not analyzed) routine, e.g. in case of tail calls.As a result, some messages may change from
No assumptions are made on the stack effects for routine 'foo'.
to
Annotation hint:ais2 { routine "_tx_thread_schedule" { obeys calling conventions: false; } }Assuming a balanced stack effect for routine 'foo'.
Annotation hint:ais2 { routine "_tx_thread_schedule" { obeys calling conventions: <bool>; } }Not analyzed code snippets are now always classified as violations of calling conventions. Consequently, the following messages will not be emitted anymore:
warning #3099:
In routine ':Anon_0x116e', at address 0x116e:
No assumptions are made on the stack effects for excluded code snippet ':Anon_0x116e'.
Annotation hint:ais2 { routine ":Anon_0x116e" { obeys calling conventions: false; } }The analyzer now informs you if an “obeys calling conventions: true” annotation has been overruled:
Info #3114: In "foo/main.c", line 12:
In routine ':Anon_0x8001620', at address thumb::0x8001620:
In "foo.ais", line 13, column 5:
The analysis assumes a violation of calling conventions for routine ':Anon_0x8001620'.
Ignoring annotation that states the opposite.
Graph visualization
- Irreducible loops are now marked in a special color.
- Annotation hints have been improved.
- Messages with identical annotation hints are now grouped.
- Recursion groups can now be extracted from the graph and displayed by themselves.
- You can now create analyses from routine nodes in call graphs.
ResultCombinator
- ResultCombinator results are now included in the XML report file.
The structure of the subtree is:
<computation_task> <computation> <expression>...</expression> <result>...</result> <expectation>success</expectation> <messages> <message>...</message> ... </messages> </computation> </computation_task> - ResultCombinator is now able to handle analysis groups (addressed via
@groupname) for min/max functors. This allows easy composition of stack results for multiple analyses:max(@StackAnalysisGroup)