- The Windows version now makes use of certain libraries it did not rely on before. Should you get a message about missing libraries on first startup, simply install the Visual C++ redistributable from Microsoft.
- We now offer a free plugin for automatic integration of Astrée in Jenkins, the leading open-source automation server.

- The alauncher executable is now used for automation of Astrée and a³
(running analyses in batch mode, e.g. within continuous-integration systems).
It provides a verbose
--help. - The Safety Manual now also covers regulations for medical devices, in particular the FDA Principles of Software Validation, and describes qualified tool workflows for Astrée and a³.
- This stable release incorporates the changes previously released as intermediate patches for release 16.04.
Performance
- Analysis precision has been improved in a number of ways:
- Modified the widening strategy for higher precision.
- Improved precision of casts from integer to floats when the integer is known not to be 0.
- More precise reachability information for expressions with side effects.
Expressions and statements that contain a sub-expression that is non-returning —
e.g. a call to
exit()or a compound expression containing jump statements — are not marked unreachable anymore. - Higher precision for dynamically allocated memory when using Astrée’s function substitution feature.
- Malloc call sites can now be distinguished using loop unrolling directives. This leads to a more precise analysis of the values stored in the dynamically allocated memory, and a finer tracking of freed memory.
- Analyses no longer stop upon encountering undeclared absolute addresses. Instead, all values written to any undeclared absolute addresses are collected and used for any read to an undeclared absolute address. In addition, when undeclared absolute addresses are encountered, a list of suggested directives that would cover such accesses is provided.
- Modified the iteration scheme for parallel processes to improve efficiency when analyzing asynchronous code.
- Fixed a widening issue that could cause very long analysis times when iterating over asynchronous processes or context-insensitively analyzed functions.
- Fixed analysis of expressions of the form
sizeof(&*a)whereais of typearray.
Stub libraries
The OS stubs for OSEK now provide more efficient implementations of the functions
EnableAllInterruptsDisableAllInterruptsSuspendAllInterruptsResumeAllInterruptsSuspendOSInterruptsResumeOSInterrupts
In addition, the effect of these functions is now more precisely
captured by the analyzer when the new Process priority domain is enabled
(precise-priorities=yes).
Server
- The server can now be locked in the server controller, such that no further analyses can be queued or started. This is useful e.g. when preparing for planned server shutdowns or upgrades.
- The server now also reports the license features that are enabled by the configured license file. This information is written to stdout as well as to the server log file.
C frontend
- Reduced memory consumption when analyzing code that contains many unused static or inline function definitions.
- Added support for linking incomplete and complete
enumtags to allow the forward declaration of enums. - Type compatibility rules have been modified as follows:
- arithmetic types of same size and signedness are no longer compatible if they are not equal
- the plain char type is no longer compatible with signed or unsigned char
- function types without prototype are now compatible to function types with prototype according to the conditions given in ISO/IEC 9899:1999
type-compatibility) and MISRA-C:2012 Appendix 1 rule 21.15 (memory-function-compatible).
Original-source frontend
- Added support for command-line macros with a replacement
starting with
=, e.g.-DEQ===. - Fixed argument substitution for operands of
#and##. The frontend now takes the original tokens of the argument instead of the expanded ones if the parameter instance is operand to one of the respective operators. - The original-source frontend now supports preprocessor macros like
#define B(X) X #define A B A(X)
where a macro nameAexpands to another macro nameBwith the macro argument list forBlying outside of the expansion result ofA. - The list of patterns to ignore (which is part of the parser configuration) is now also applied to preprocessor directives in original-source files. Matching patterns are removed before checking coding rules.
Known issues
- When enabling the gauge domain, in rare cases the analyzer may underestimate the value ranges of certain variables. Make sure that the gauge domain is disabled (this is the default setting of the analyzer), or contact support@absint.com for details on scenarios that trigger the undesired behavior.
- In order to update already existing preprocessed files on the server
after preprocessing, at least one of the following options must be set:
- “Synchronize preprocessed files” under Project → Preferences
- “Remove analysis files before importing preprocessed files” under Configuration → Preprocessor
- In batch mode, the coverage information is missing from the XML result file unless it is needed to generate some reports.
- When using the ABI option
rounding_mode=to_nearest, the analysis might stop in some contexts when evaluating a guard expression that involves a binary operation on floats. - When using the option
exclude-signed-in-unsigned-overflows(“Do not raise overflow alarms on unsigned computations with signed values”), the analyzer might crash in certain scenarios.
The last two issues are fixed in Release 16.10 Patch 1 (build 271444).
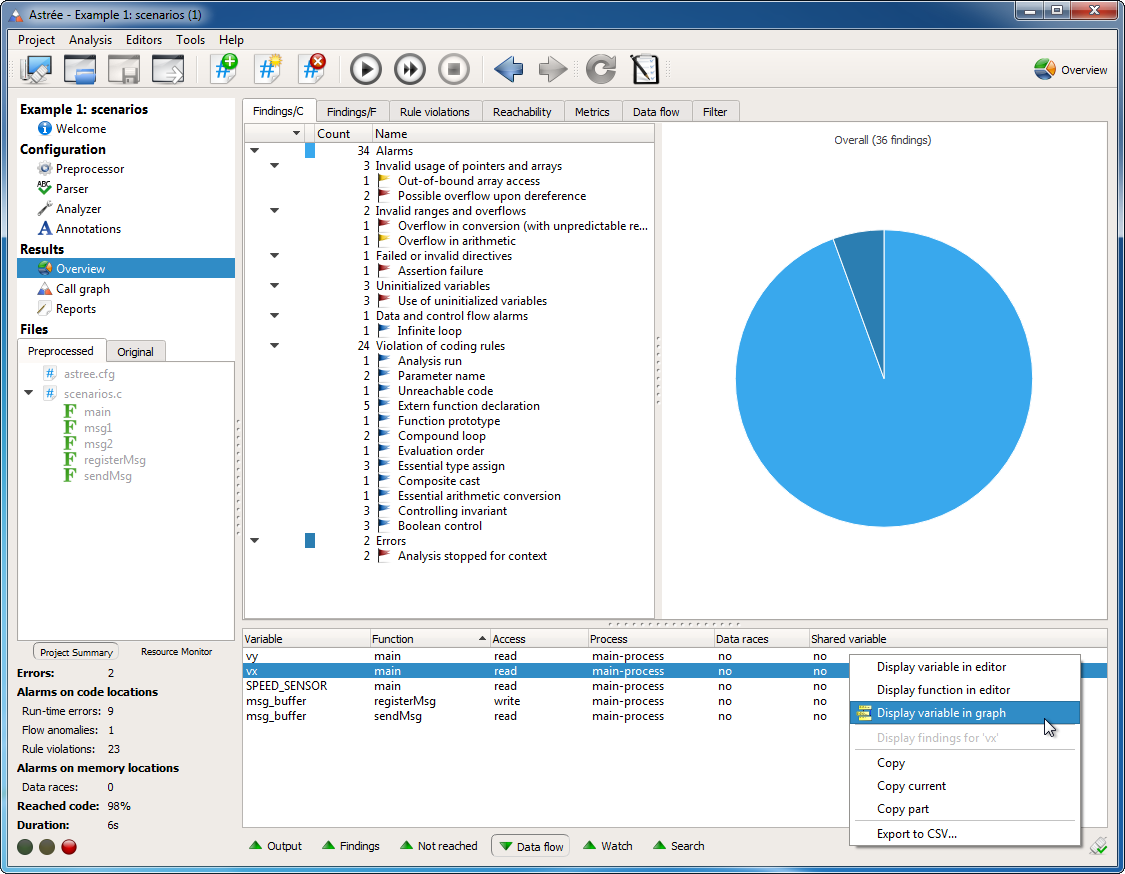
Data Flow view
The new Data Flow view in the Results area displays all data flow information collected by the analyzer. All accesses to global/static variables are shown, with information about whether they are shared or involved in a data race, what kind of access it is, and from which function or process it originates. The context menu in this view gives access to the corresponding code locations.
You can interactively query the data flow information based on a selection of relevant variables, functions, and processes. These queries are applied as filters to the Data Flow view. This is particularly helpful for identifying all processes and accesses contributing to a data race.
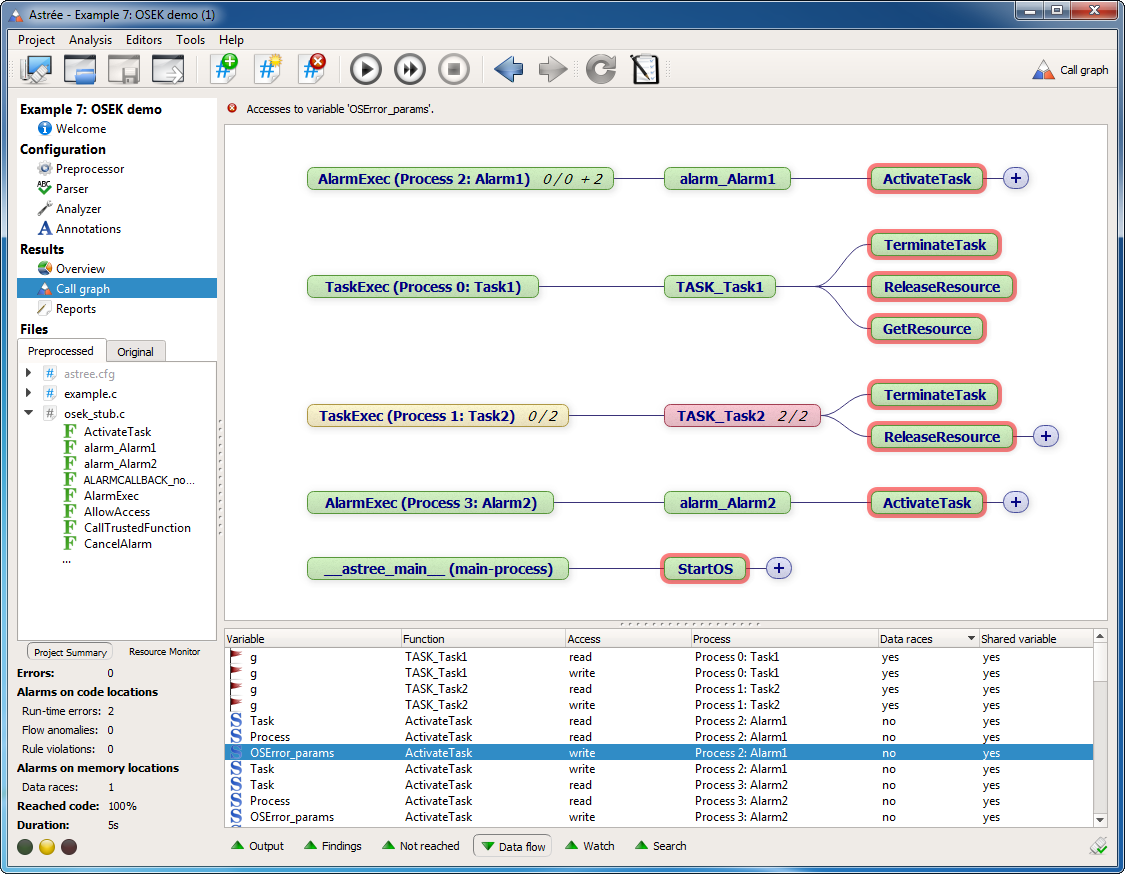
Call graphs
The Call Graph view can now show all possible call paths for accesses to global variables. This feature is activated in the Data Flow view via the context menu entries “Display in graph” and “Display variable in graph”. It is particularly useful when investigating shared variables and data race alarms.
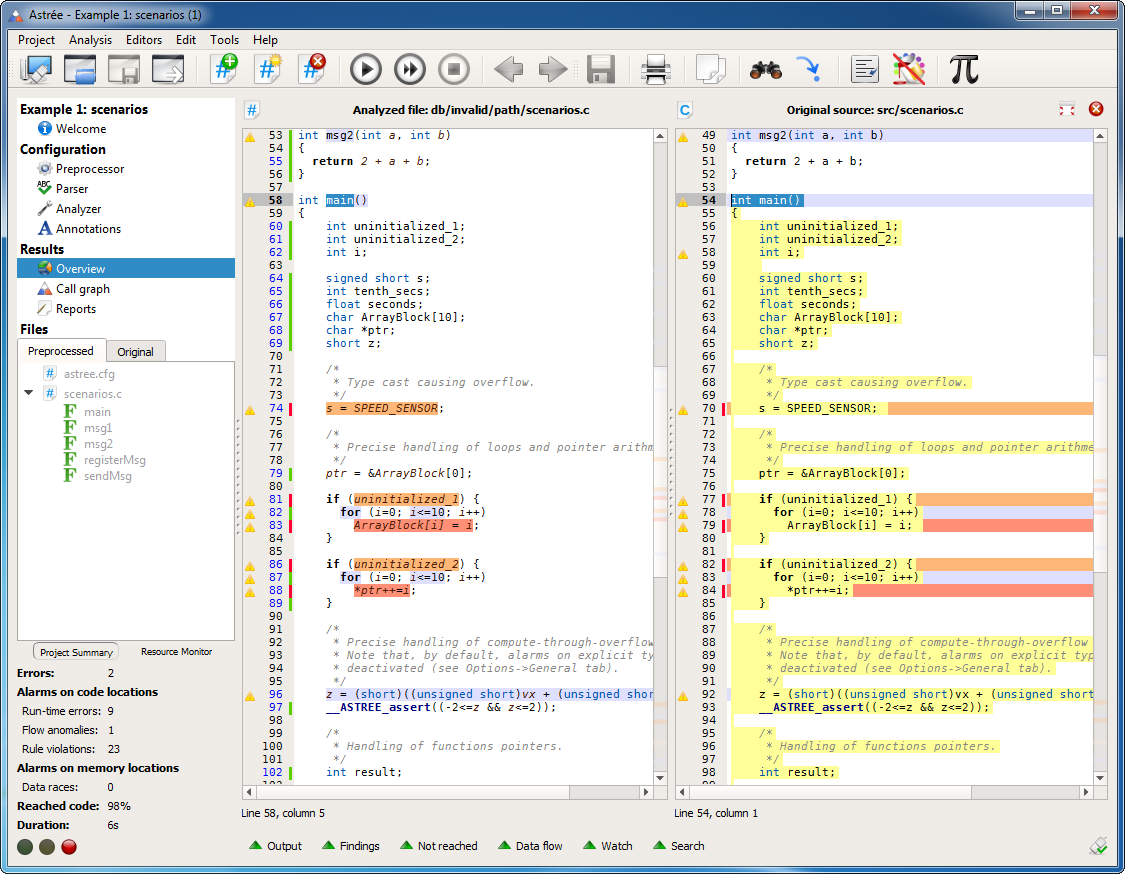
Editor views
- Analyzed code lines without errors or alarms of type A, B, or C are now marked in green. These lines are proven to be free of runtime errors and data races under the assumptions made by the analyzer.
- Exclamation marks denote code lines for which there are alarms of type A, B, C, D, R, or other notifications. Clicking on an exclamation mark takes you to the corresponding findings in the Findings view.
- The availability of invariants for display in the Watch view is now denoted by blue line numbers rather than a blue bar.
Filtering
- The files list in the Results → Overview → Filter view can now be filtered for occurrences of text strings or regular expressions. This enables long file lists to be quickly filtered to match your criteria.
- The list of analysis projects in the “Open project” dialog can now be filtered by pressing Ctrl+F.
- Improved filtering in the Findings view now requires fewer clicks for displaying the list of findings without comment.
- The type filter in the Findings view is no longer reset to default when starting an analysis.
Wrapper generator
- You can now generate a wrapper with initialization functions only, but without tasks.
- For asynchronous execution models, the wrapper generator
now generates entry code that uses the analyzer intrinsic
functions
__astree_create_process()and__astree_start_process()instead of the no longer supported__ASTREE_asynchronous_loopdirective. Consequently, the wrapper generator takes an optional priority argument for tasks and task entry functions can no longer take parameters. - The wrapper generator now warns before overwriting an existing wrapper-and-stubs file. It then also offers the option of appending the new code to the existing wrapper-and-stubs file, rather than overwriting its contents.
Other changes to the GUI
- An overview of analysis time broken down by different project parts is now available under Tools → Analysis time. It can be accessed as soon as the analysis has started and is updated on-the-fly.
- The Report view has been redesigned. Directories and file names
for report files can now be freely chosen, like in the DAX
<report>specification. Moreover, it is now possible to define and generate customized HTML reports. For further details, see the Results tab of these release notes. - Simplified the configuration of rule checks. It is now easier to activate rules within deactivated sections and to enable or disable categories of MISRA rules (Required, Advisory, etc.).
- Removed the extra stop button from the Preprocessing view. The preprocessing can now be stopped by the stop button in the toolbar that is also used for stopping the analysis.
- Improved value tooltips: for expressions of the form
a->bthe GUI now displays not only a tooltip for the whole expressiona->bbut also for the sub-expressiona. Moreover, it now also shows the values of indices in array accesses (e.g.a[i]) even if such expressions appear on the left-hand side of assignments. - The memory usage graph in the resource monitor now covers the entire duration of the analysis.
- Improved the ordering of revisions in the result difference charts of the Differences viewer. They are now ordered by analysis start time.
- Fixed loading original source files with file names containing special characters (like é or ì).
- Improved responsiveness and reduced memory consumption of the client GUI for analysis projects with millions of functions.
- Improved the import of AAL annotations.
It now ignores all annotation file contents
that do not appear inside of an
__ASTREE_annotationblock. - If the DAX export option “
ExportAll” is selected, the GUI now also exports rules with parameters displayed as<empty>. - When a location is highlighted in the editor, e.g. by clicking on an alarm in the Findings view, the location is now centered in the editor.
- Improved performance when commenting alarms in analysis projects containing large files with many declarations.
- Improved error reporting in case of an expired license file.
- Removed the “Generate annotations” button from the Findings view. Generating the annotations is now part of the Project → Save action which is also accessible from the toolbar or via the global Ctrl+S keyboard shortcut.
- The collapsed or expanded state of elements in the annotations view is no longer reset by delete or insert operations.
- The “Copy part” mode for copying parts of an analyzer message from the Output view can now also be entered by double-clicking on a line.
- The differences viewer for comparing revisions of analysis projects now differentiates between the different kinds of findings: runtime errors, data races, rule violations, etc.
- Fixed the global counter for memory locations involved in data races, which is displayed in the Summary area. (In certain rare cases, this number was too small.)
Improved and extended reports
- New customizable HTML reports that can be configured in both the GUI and in DAX. The configuration options provide all reporting features of the XML summary reports and additional options that correspond to the different operating modes of the Overview view in the GUI.
- The result summary in the analyzer log now also displays the number
of proven statements:
/* Result summary */ ... Reached code: 98 % (51/52 statements reached, 45/51 (88 %) statements proven) ...
A statement is proven if it is reached by the analysis and does not cause an error or an alarm of type A, B or C. - Error messages about incompatible types are now added to the error summary counter of the analyzer, which is printed in the text report and the Output view in the GUI.
- The analyzer now also outputs the patterns to ignore
and external declarations of the parser configuration:
/* Filter patterns */ function: asm void identifier: __compiler_extension__ regexp: asm([^)]+); identifier: asm /* External declarations */ type: my_type; declaration: my_type my_function(my_type, int);
- Improved reporting of potentially shared variables.
The analyzer now prints a detailed list of all variables
that may be accessed from more than one process.
The corresponding option
report-shared-variablesis now active by default./* Possibly shared variables */ 'Process' at osek_stub.c:890.20-27 | read/written in Process 0: Task1 | | read/written in Process 1: Task2 | | read in Process 2: Alarm1 | | read in Process 3: Alarm2 |
- Added new output of deadlock cycles and alarms
about deadlocks.
ALARM (D): lock operation can cause a deadlock (deadlock-cycle #1: process 0 locks 0, process 1 locks 1) at ...
The deadlock cycles that these alarms belong to are displayed in the Output view of the GUI and in the text report:
ALARM (D): lock operation can cause a deadlock (deadlock-cycle #1: process 0 locks 0, process 1 locks 1) at ...----- deadlock-cycle #1: ---------- [ at ... participant: [process 0, locked: {1} ] lock 0] [ at ... participant: [process 1, locked: {0} ] lock 1]A deadlock cycle is a list of processes in a given state trying to acquire a lock which is taken by another element of the list. Each element of the list is printed with relevant context information (call stack and position in the code where the lock is taken). The new alarms and output are disabled by default and can be activated by the new optionwarn-on-deadlocks=yes. - Alarm messages about data races now indicate
whether the access path is volatile and atomic.
ALARM (B): write-write data-race on atomic access in assignment 2 byte(s) at ...
Alarm messages with the additional information “on atomic access” are exactly those data races that are not reported if the new optionwarn-on-atomic-volatile-data-raceis disabled. - The parsing phase of the analyzer now ends with the line
Parsed X physical lines of preprocessed code
where X is the number of preprocessed source lines containing at least one non-whitespace C token, excluding line directives and filtered code. This line is also contained in the text report file. - Alarms about "Wrong range of second shift argument" have been moved from the category "Invalid ranges and overflows" to the new category "Invalid shift argument". This modification affects the GUI and the XML report file.
- Added a new category of alarms named “Overflow in conversion (with unpredictable results)” for collecting float-to-integer conversions that overflow the range of the target integer. The type of such overflow alarms has been changed to A. After the overflow, the analyzer continues with the full range of the target integer type.
- Astrée now raises additional alarms when comparing
or copying dangling pointers. The result of copying
a dangling pointer is an invalid pointer. For example,
analyzing the following code
char* ptr = (char*)malloc(42); free(ptr); if (ptr != NULL) {results in the alarm messageALARM (A): use of dangling pointer { DANGLING: <memory-block> } at <location>
where <memory-block> is the internal name of the memory block that the pointer points to and <location> specifies the file, line and column number where the pointer is used. - The analyzer now distinguishes consistently between
an expression of the form
&*eand its sub-expressione. If both expressions raise alarms, these alarms will no longer be coalesced to the same code location for the purpose of counting alarms per code location. - Improved the display of invariants for bitfields in tooltips
and
__ASTREE_log_varsto use proper names. That is, for code of the formstruct { char a:4; char b:4;} x; x.b = 2;the information forx.bis now displayed asx.b in {2}. - The Astree XML Result File format now has an XML schema definition file, to be found at absint.com/dtd/astree-dax-report-configuration-16.10.xsd.
- Invalid AAL paths for alarm comments are no longer reported as errors, but merely as notifications. The change was made because comments have no effect on the program semantics assumed by the analyzer. Invalid AAL paths used for inserting other directives are still reported as errors.
- The analyzer’s progress message for global iterations
no longer distinguishes between parallel and separate analysis modes.
Here is the new output for such iterations as displayed in the Output
view and text report:
global iter #5
global iter #5 (widened) - The XML report now also contains the parser configuration,
i.e. the list of external declarations and patterns to ignore.
<parser_ignore> <pattern type="function">foobar</pattern> <pattern type="identifier">foo</pattern> <pattern type="regexp">bar.*</pattern> <pattern type="pragma-asm">yes</pattern> </parser_ignore> <external_declarations> <external_declaration type="type">T;</external_declaration> <external_declaration type="declaration">T x;</external_declaration> </external_declarations>
- The XML report may now contain alarm messages without location information.
Currently the only alarms of this kind are violations of MISRA-C:2004 rule 21.1
and MISRA-C:2012 rule D.4.1 in cases where the rule check
analysis-runfails. - The message
NOTE: translate_warning(type): conversion from floating-point to integer: from <TYPE> to <TYPE> at <LOCATION>
has been removed. Instead we recommend activating the MISRA-C:2012 rule 10.3 or the MISRA-C:2004 rule 10.2. - If the right-hand side of a logical expression is reached by the analyzer, it is now always properly marked as reached.
- Fixed the global counter for memory locations involved in data races
in the XML report file., i.e. the number given in the
data_racesattribute of the<summary>tag. (In certain rare cases, this number was too small.)
Code metrics
- Statement expressions (GCC compiler extension) are now taken into account when computing metrics. For the purposes of the LSCOPE (language scope) metric, they are considered to be operators.
- LSCOPE now also takes into account the semicolon of null statements
and statements in implicit control blocks (like branches of an
ifstatement that are not enclosed in brackets).
Standalone RuleChecker
Most of the supported MISRA rules can now be checked for without running
the runtime error analysis (skip-analysis=yes):
- The check for recursion now has two implementations
with varying precision that are chosen depending
on the value of
skip-analysis. - The new check
controlling-invariant-expression, associated with MISRA-C:2004 rule 4.1 and MISRA-C:2012 rule 2.1, provides a partial coverage for those rules without runtime error analysis. - Likewise, the check
uninitialized-variable-use(rule 9.1 of both MISRA-C:2004 and MISRA-C:2012) checks for missing initializers if the runtime error analysis is disabled. - The following checks have been split in two
to gain a partial check that does not rely on the analysis:
error-information-unused ⤙ error-information-unused
error-information-unused-computedshift-width ⤙ shift-width
shift-width-constantessential-shift-width ⤙ essential-shift-width
essential-shift-width-constantparameter-match ⤙ parameter-match
parameter-match-computedboolean-invariant ⤙ boolean-invariant
boolean-invariant-expressioncontrolling-invariant ⤙ controlling-invariant
controlling-invariant-expression
MISRA-C:2004
- Added support for rule 18.2.
- The following rule checks have been added to cover the aspect of
“implementational limits” (as defined in ISO/IEC 9899:1990 p2.2.4.1)
of rule 1.1:
max-arguments-macromax-case-labelsmax-condition-nestingmax-declarator-depthmax-declarator-nestingmax-enumsmax-expression-nestingmax-externalsmax-include-nestingmax-localsmax-logical-line-lengthmax-macros-definedmax-membersmax-parametersmax-parameters-macromax-statement-nestingmax-string-lengthmax-struct-nestingparameters
- New checks for rule 15.0:
switch-skipped-code
warns about statements or declarations preceding the first switch clauseswitch-clause-empty-compound
warns about switch clauses consisting of only an empty compound statement, e.g.default: {}
- Fixed checks for rule 8.4. See the section on the C frontend for further details.
- The check
function-return-typehas been moved from rule 8.1 to rule 8.2. - The checks for rule 8.1 now also warn about implicit function declarations and function definitions without a preceding declaration of that function.
- The check
evaluation-orderfor rule 12.2 is now also performed in initializer expressions. - The check for rule 11.3 has been improved to also cover implicit conversions.
MISRA-C:2012
- Amendment 1 is now supported, which adds new rules
and modifies rule 21.8. The new rules use the prefix
M2012A1followed by the MISRA rule number. - Added support for rule 19.1.
- New checks for rule 16.1:
switch-skipped-code
warns about statements or declarations preceding the first switch clauseswitch-clause-empty-compound
warns about switch clauses consisting of only an empty compound statement, e.g.default: {}
- Read accesses are now only treated as persistent side effects if they are syntactically volatile. This affects rules 13.1, 13.2, 13.5, and 14.2.
- Fixed check
for-loop-condition-sideeffectfor the case when the third expression of a for-loop is missing. This affects rule 14.2. - Fixed check
side-effect-in-initializer-listfor initializer lists with a single element. This affects rule 13.1. - The check
evaluation-orderfor rule 13.2 is now also performed in initializer expressions. - The check
function-return-typehas been moved from rule 8.2 to rule 8.1. - Fixed false alarm about violation of rule 6.2
when using the
_Booltype. - Fixed false alarms about violation of rule 13.3
when performing the check
unary-assign-detachmentin combination with volatile variables. - The checks for rules 11.1 and 11.4 have been improved to also cover implicit conversions.
Both rule sets
The checks for the MISRA-C:2004 rules 11.4 and 11.5 and for the MISRA-C:2012 rules 11.3, 11.6, 11.7, and 11.8 have been extended to cover implicit conversions.
- Added the checks
pointer-qualifier-cast-implicitinappropriate-pointer-cast-implicitobject-pointer-diff-cast-implicitobject-pointer-diff-cast-strict-implicit
- Split the check
cast-pointer-void-arithmetic ⤙ cast-pointer-void-arithmetic
cast-pointer-void-arithmetic-implicit - Added
pointer-qualifier-cast-implicitto rule 1.1.
Customer-specific rules
- Fixed false alarm in rule X.A.4.8 for comment sequences of the form
/* comment1 *//* comment2 * comment2 continued */
- Corrected documentation of rule X.A.3.9.
- The rule X.A.4.3 can now be modified by a regular expression parameter.
Extensions of the DAX format
- New DAX version 1.3.
- External declarations are now specified in DAX
rather than in an
.edffile. Here is an example that shows the new DAX tags:<external-declarations> <type>typeA</type> <type>typeB</type> <declaration>typeA f(int)</declaration> <declaration>typeB g(typeA, int)</declaration> </external-declarations>
- The DAX export from the GUI has been adapted accordingly.
Old DAX and
.edffiles can still be imported. - The ABI settings have been extended for specifying pointers
of different size. Here is an example that shows all new DAX tags:
<abi> <sizeof_attributed_pointer_1>2</sizeof_attributed_pointer_1> <alignof_attributed_pointer_1>2</alignof_attributed_pointer_1> <atomic_attributed_pointer_1>no</atomic_attributed_pointer_1> <pointer_attributes_1>_near,_xnear</pointer_attributes_1> </abi>
- The ABI settings have been extended to include information
about whether aligned accesses to the different basic data types are atomic:
Information about atomically accessible data types has been added to the pre-defined ABIs where appropriate.
ABI key DAX tag atomic_bool <atomic_bool>yes|no</atomic_bool> atomic_char <atomic_char>yes|no</atomic_char> atomic_short <atomic_short>yes|no</atomic_short> atomic_int <atomic_int>yes|no</atomic_int> atomic_long <atomic_long>yes|no</atomic_long> atomic_long_long <atomic_long_long>yes|no</atomic_long_long> atomic_float <atomic_float>yes|no</atomic_float> atomic_double <atomic_double>yes|no</atomic_double> atomic_long_double <atomic_long_double>yes|no</atomic_long_double> atomic_pointer <atomic_pointer>yes|no</atomic_pointer> atomic_function_pointer <atomic_function_pointer>yes|no</atomic_function_pointer> - For asynchronous execution models, the
parametersattribute of the<task>tag in the<wrapper>section has been replaced by a newpriorityattribute:<wrapper> <task priority="50">Task0</task> <task priority="100">Task1</task> <execution-model>asynchronous</execution-model> </wrapper>
- The DAX format has been extended by a
<report-configuration>section that allows the definition of customized reports. The extension is defined in a separate XML schema that is included by the XML schema for DAX. The schema can be found at absint.com/dtd/astree-dax-report-configuration-16.10.xsd.
Updates to the TargetLink coupling
- The TargetLink importer settings are now shared between all clients. For analysis projects created with older versions of Astrée, the settings are taken from the first user that opens the old project and then saves it.
- “Import Result from XTC File” now puts the result into
a new
AbsIntAnalysisResultselement of the function instead of writing to the function’s properties directly. - Missing source files are no longer added to the analysis configuration. Instead the toolbox prints a warning message.
- The Astrée Server Settings dialog now also lists Astrée versions that were not installed in the default location.
- The Data Dictionary file in the TargetLink Data Dictionary Importer file can now be specified using a relative path. Relative paths are extended with the global base directory specified in the Preprocessor view.
Jenkins and Eclipse plugins
- Initial release of the Jenkins plugin for Astrée.
- First public announcement of the Eclipse plugin for Astrée.
Batch mode
- Progress information is now printed to stdout:
Progress: [13:45:13]: Processing DAX... Progress: [13:45:13]: Importing... [...] Progress: [13:45:14]: Analyzing... Progress: [13:45:30]: Analysis done...
- For any error that occurs during preprocessing, the text report file now includes the preprocessor command line that caused it.
General configuration
Modified the interpretation of preprocessing configurations w.r.t. the use of relative paths as their base directory. Such paths are now extended by prepending the base directories of all parent configurations up to the global base directory. This path extension terminates at the first base directory that is specified as an absolute path. Example:
<base>C:/tmp/my_code/</base>
<config name="libs">
<base>lib</base>
<config name="extra files">
<base>extra</base>
<files>
<file>file.c</file>
</files>
</config>
</config>
This DAX configuration specifies the following file for preprocessing:
C:/tmp/my_code/lib/extra/file.c
The same path extension is also applied to include paths and is also performed when configuring the preprocessor in the GUI.
Options
- New options:
precise-priorities(defaultno)
Only applies to analyses of concurrent software. Activates a new domain for more precise handling of process priorities including dynamic priorities (e.g. according to the Priority Ceiling Protocol). Generally this leads to higher analysis times, but yields significantly more precise results.warn-on-deadlocks(defaultno)
Activates detection of deadlocks in asynchronous software. See the Results tab of these release notes for further details.warn-on-atomic-volatile-data-race(defaultyes)
When this option is set tono, no data race will be reported for accesses to memory through lvalues that are qualified as volatile and have a type declared as atomic in the ABI specifications. This is particularly useful for analyzing lock-free implementations of concurrent behavior.at-location(enabled by default)
Controls whether Astrée supports@<address>declarations (compiler extension) for data placement at an absolute location. If enabled, the analyzer considers the following declarationint i @0x1234;
to be equivalent toint i; __ASTREE_absolute_address((i, 0x1234));
That is, the declared variable is known to be allocated to the given absolute address. The address can also be specified as a constant expression.- It is now possible to specify how bitfields should be treated
with respect to data races. By default, concurrent bitfield accesses
within the same byte are reported as data races. When using the new
option
bitfield-data-race-enclosing-bytes-only=no, bitfield accesses are considered to interact with all bitfields contained within the boundaries of the type used in their definition.
- Removed options:
automatic-shared-variables
Shared variables are now always automatically detected.constant-propagation
Constant propagation is now always used when evaluating constant expressions. In addition, it is used for source code simplification if thesimplifyoption is enabled. That is,simplify=yesnow behaves likesimplify=yes constant-propagation=yesin earlier releases.
- The option
partition-pt1now takes an integer value as argument instead of the previousyes/no. The integer value specifies into how many partitions the values of PT1 filters are divided by the analyzer. The default value is3, which was the value used withpartition-pt1=yesin earlier Astrée releases. Values less than2disable partitioning of PT1 filters. Values greater than3increase precision up to a certain limit. When converting old analysis projects or importing them via AAF or DAX, the old valueyesis automatically converted into3, whilenois converted into0. - The default value of
stop-parse-error-immediatehas been changed tono, i.e. the option is now disabled by default. - With the option
stop-parse-error-immediate=no, parse errors no longer stop the rule checking on preprocessed files completely. Instead it is performed on all successfully parsed files.
Directives
- The directives
__ASTREE_asynchronous_loopand__ASTREE_shared_variableare not supported anymore. Asynchronous tasks should be declared using__astree_create_processand__astree_start_process. - The directive
__ASTREE_known_rangenow accepts parenthesized expressions again:__ASTREE_known_range(( (*p)[], [0;100] ));
This was temporarily unsupported in release 16.04. - The
__ASTREE_absolute_addressdirective now accepts not only constants but also constant expressions as absolute addresses. - When encountering an invalid
__ASTREE_absolute_addressdirective, the analyzer no longer stops. Instead it reports the error and carries on with the analysis. The invalid directive is ignored. - In release 16.04 the
__ASTREE_absolute_addressdirective was unintentionally accepted in function scope (and ignored for function local variables). It is now strictly rejected in function scope and only allowed on the global level as documented.
ABI
- The analyzer now supports pointers of different sizes
which are provided by many compilers for accessing objects
placed in different memory regions. A typical example are
'near' and 'far' pointers. To this end, the ABI settings allow
the configuration of up to three additional 'attributed'
pointer types. Each 'attributed' pointer has its own size,
alignment, and atomicity settings. An additional list
of attributes specifies the keywords that are used
to declare a pointer of this kind. The given size information
is used by the analyzer to calculate the correct layout
of other types. The new ABI keys and DAX tags are:
sizeof_attributed_pointer_1alignof_attributed_pointer_1atomic_attributed_pointer_1pointer_attributes_1
- Updated the ABI for c166 to respect the
__near,__xnear,__far,__huge, and__shugeattributes for pointers. - Added ABI for IAR on RL78 with data model "Near".
- The ABI settings have been extended by information
about whether aligned accesses to the different basic
data types are atomic. The new ABI keys are constructed
by adding the prefix
atomic_to a basic data type, e.g.atomic_bool,atomic_char,atomic_short. Information about atomically accessible data types has been added to the pre-defined ABIs where appropriate. - Corrected the values for the long double type in the pre-defined ppc32diab ABI.
Patch 1 (build 271444)
Fixed the following known issues:
- When using the ABI option
rounding_mode=to_nearest, older builds of the analyzer might stop in some contexts when evaluating a guard expression that involves a binary operation on floats. - When using the option
exclude-signed-in-unsigned-overflows(“Do not raise overflow alarms on unsigned computations with signed values”), older builds of the analyzer might crash in certain scenarios.
{kind=link}
{kind=link}